Well thankfully I've returned from my stint over 200 clicks north of the arctic circle with all my fingers and toes! Mind you, we were lucky to catch some unseasonably warm weather - the coldest it got was a toasty -3 (celsius) instead of the average -20 at this time of year.
Anyhou, I've been working on a bit of a special rant philosophical post to end the year, so I'll get my well wishes out of the way now.
I hope you've had a great 2008. I had almost zero expectations when I started this blog back in January, and have been completely blown away at the level of readership and attention in the community that I have received. So to that end, thanks everyone for reading, thanks to the guys in the community I talk to / know (they're listed in the "linkage" section down the right there). Thanks to John Troyer at VMware for helping to get me on the map and for being so tolerant with the profanity ;-), and thanks to all the other people at VMware who have helped along the way... Lance, Carter, Steve, the account team that handles my company (you think I give VMware a hard time as a blogger... that's nothing compared to what I put them through as a customer). And a special shout out to all those who took the time to email me over the year - I really appreciate the time anyone takes to give me their angle or experiences with regards to a post, keep it coming.
In the new year I'll be moving to dedicated hosting, so hopefully I can start doing some more stuff like hosting a few whitepapers and small utilities / scripts. And get a bit more of a custom theme going (the green ain't going nowhere though ;-).
The coming year is going to be interesting for many people on many fronts, and I don't expect it will be an easy one. But as Albert Einstein said, "In the midst of difficulty lies opportunity". Here's wishing that you all make the most of those opportunities should they arise, and have a great 2009.
Tuesday 30 December 2008
Wednesday 24 December 2008
Merry Christmas!
Just a quick note to say Merry Christmas to everyone. I'll be ducking off to try and catch the Northern Lights between now and new years, including a stint of sleeping on ice. Should be cool (ho ho ho, pun fully intended!). Wherever you are, I hope you have a safe and happy festive season.
Sunday 21 December 2008
It's Beginning to Look a Lot Like Citrix...
VDI that is. Technically that should say 'terminal services', but I had to get in a Christmas themed post title before the 25th :)
Remember back when VDI reached that tipping point in the enterprise? It was hailed as offering unprecedented levels of flexibility. Hailed as the slayer of terminal server based environments with their draconian mandatory profiles and restricted application sets. And biggest of all, hailed as finally providing us with a unified environment for application packaging, support and delivery. And so we all embarked on this VDI journey. But of course, there is a difference between knowing the path and walking the path. And having travelled this road for a while now, a sense of déjà vu is creeping in.
Yes, it is decidedly feeling a lot like Citrix. In an effort to drive down costs, the VDI restrictions and caveats are coming out of the woodwork. Scheduled desktop "refreshes", locking down desktop functionality in the name of stopping writes to the system drive, redirecting profiles to other volumes, squeezing a common set of required applications into a base 'master' template and disallowing application installs, etc etc. Software solutions are being ushered in to address these issues (brokers, app virtualisation, user environment virtualisation) - all for a premium of course. The same way it happened with Terminal Services / Citrix. We need to buy Terminal Server CALs from Microsoft, Citrix CAL's from Citrix, pay additional for enterprise features like useful load balancing, even more for decent reporting capabilities, then we need to do something about profile management, we need separate packaging standards, there are separate support teams, separate application compatibility and supportability issues, etc etc.
If we continue to slap all these restrictions and add all these infrastructure / software (ie cost) requirements on top of VDI, we run the risk of turning it into the very thing we were trying to get away from in the first place. The problem is without them, VDI doesn't provide a cost effective solution for _general desktop replacement in well connected environments_ yet. I'll emphasize the important bit in that sentence, in bold caps so I'm not misunderstood. _GENERAL DESKTOP REPLACEMENT IN WELL CONNECTED ENVIRONMENTS_. There are of course loads of other use cases where VDI makes great sense. But a desktop replacement for the average office worker in a well connected environment ain't one of them.
And the desktop requirements for the average office worker is on the rise. In this new world of communication, IM based voice and video is coming to the fore. And yet none of the big players in the VDI space have a solution for universal USB redirection or high quality bi-directional audio/video to remote machines. But does it even make sense to develop such things? Either way, you still have a requirement for local compute resources and a local operating environment in which these devices can be used. Surely it makes more sense to use that local machine for the minimal desktop and applications that use this hardware (VOIP clients, etc), and remote all the other apps into the physical machine from somewhere else?
Maybe we'd be better off parking those plans for VDI world domination for the moment, and focusing on next generation application delivery and user environment virtualisation for our current desktop infrastructure (both physical and virtual). Once those things are in place, we will be in a much better position to assess just how much sense VDI really makes as a general desktop replacement.
Remember back when VDI reached that tipping point in the enterprise? It was hailed as offering unprecedented levels of flexibility. Hailed as the slayer of terminal server based environments with their draconian mandatory profiles and restricted application sets. And biggest of all, hailed as finally providing us with a unified environment for application packaging, support and delivery. And so we all embarked on this VDI journey. But of course, there is a difference between knowing the path and walking the path. And having travelled this road for a while now, a sense of déjà vu is creeping in.
Yes, it is decidedly feeling a lot like Citrix. In an effort to drive down costs, the VDI restrictions and caveats are coming out of the woodwork. Scheduled desktop "refreshes", locking down desktop functionality in the name of stopping writes to the system drive, redirecting profiles to other volumes, squeezing a common set of required applications into a base 'master' template and disallowing application installs, etc etc. Software solutions are being ushered in to address these issues (brokers, app virtualisation, user environment virtualisation) - all for a premium of course. The same way it happened with Terminal Services / Citrix. We need to buy Terminal Server CALs from Microsoft, Citrix CAL's from Citrix, pay additional for enterprise features like useful load balancing, even more for decent reporting capabilities, then we need to do something about profile management, we need separate packaging standards, there are separate support teams, separate application compatibility and supportability issues, etc etc.
If we continue to slap all these restrictions and add all these infrastructure / software (ie cost) requirements on top of VDI, we run the risk of turning it into the very thing we were trying to get away from in the first place. The problem is without them, VDI doesn't provide a cost effective solution for _general desktop replacement in well connected environments_ yet. I'll emphasize the important bit in that sentence, in bold caps so I'm not misunderstood. _GENERAL DESKTOP REPLACEMENT IN WELL CONNECTED ENVIRONMENTS_. There are of course loads of other use cases where VDI makes great sense. But a desktop replacement for the average office worker in a well connected environment ain't one of them.
And the desktop requirements for the average office worker is on the rise. In this new world of communication, IM based voice and video is coming to the fore. And yet none of the big players in the VDI space have a solution for universal USB redirection or high quality bi-directional audio/video to remote machines. But does it even make sense to develop such things? Either way, you still have a requirement for local compute resources and a local operating environment in which these devices can be used. Surely it makes more sense to use that local machine for the minimal desktop and applications that use this hardware (VOIP clients, etc), and remote all the other apps into the physical machine from somewhere else?
Maybe we'd be better off parking those plans for VDI world domination for the moment, and focusing on next generation application delivery and user environment virtualisation for our current desktop infrastructure (both physical and virtual). Once those things are in place, we will be in a much better position to assess just how much sense VDI really makes as a general desktop replacement.
Monday 15 December 2008
Sunday 14 December 2008
Kicking ESX Host Hardware Standards Down a Notch
The hardware vs software race is becoming more and more a hare vs tortoise these days, with the advent of multicore. And you can understand why - concurrency is hard. _Very_ hard. But oddly enough, I don't see much on the intertubes about people changing their hardware standards, except for the odd bit of marketing.
Although the HP BL 495c is in some respects an interim step to where we really want to go (think PCIe-V), the CPU / memory design of the blade is pretty much spot on. That is, as more cores become available, we should be moving to less sockets and more slots.
I'm not going to entertain the whole blade vs rackmount debate. I totally understand that blades may not make much sense in small shops (places with only a few hundred servers). I probably should change the description of my blog... I only talk enterprise here people. Not small scale, not internet scale, but enterprise scale (although to be honest a lot of the same principles apply to enterprise and internet scale architectures, on the infrastructure side at least).
The next release of VMware Virtual Infrastructure will make this even more painfully obvious. VMware Fault Tolerance was never designed for big iron - it's designed to make many small nodes function like big iron. OK, so maybe the hare vs tortoise comparison isn't really fair with regards to VMware ;-).
But this doesn't only apply to ESX host hardware standards - it should apply to pretty much any x86 hardware standards, _especially_ those targetted at Windows workloads. We've seen it time and time again - even if the Windows operating system did scale really well across lots of cores (and it won't until 2008 R2), the applications just don't. We only need to look at the Exchange 2007 benchmarks that were getting attention around the time of VMworld Europe 2008 for evidence of this. If Exchange works better with 4 cores than it does 16, you can bet your life that 99.999% of Windows apps will be in the same boat. Giving your business the opportunity to purchase the latest and greatest 4 way box will do nothing but throw up artifical barriers to virtualisation. The only Windows apps that require so much grunt are poorly written ones.
So if you haven't revisited your ESX host hardware standards in the past year or so, it's probably time to do so now, so you can be ready when VI.next finally drops. Concurrency may be hard, but I wouldnt call distrubted processing easy either - the more the underlying platform can abstract these difficult programming constructs, the more easy it will be to virtualise.
Although the HP BL 495c is in some respects an interim step to where we really want to go (think PCIe-V), the CPU / memory design of the blade is pretty much spot on. That is, as more cores become available, we should be moving to less sockets and more slots.
I'm not going to entertain the whole blade vs rackmount debate. I totally understand that blades may not make much sense in small shops (places with only a few hundred servers). I probably should change the description of my blog... I only talk enterprise here people. Not small scale, not internet scale, but enterprise scale (although to be honest a lot of the same principles apply to enterprise and internet scale architectures, on the infrastructure side at least).
The next release of VMware Virtual Infrastructure will make this even more painfully obvious. VMware Fault Tolerance was never designed for big iron - it's designed to make many small nodes function like big iron. OK, so maybe the hare vs tortoise comparison isn't really fair with regards to VMware ;-).
But this doesn't only apply to ESX host hardware standards - it should apply to pretty much any x86 hardware standards, _especially_ those targetted at Windows workloads. We've seen it time and time again - even if the Windows operating system did scale really well across lots of cores (and it won't until 2008 R2), the applications just don't. We only need to look at the Exchange 2007 benchmarks that were getting attention around the time of VMworld Europe 2008 for evidence of this. If Exchange works better with 4 cores than it does 16, you can bet your life that 99.999% of Windows apps will be in the same boat. Giving your business the opportunity to purchase the latest and greatest 4 way box will do nothing but throw up artifical barriers to virtualisation. The only Windows apps that require so much grunt are poorly written ones.
So if you haven't revisited your ESX host hardware standards in the past year or so, it's probably time to do so now, so you can be ready when VI.next finally drops. Concurrency may be hard, but I wouldnt call distrubted processing easy either - the more the underlying platform can abstract these difficult programming constructs, the more easy it will be to virtualise.
Saturday 13 December 2008
Check out Martin Ingram on DABCC...
While I'm a little insulted that Martin didn't tell me he is now contributing to Doug Brown's excellent site (j/k Martin :-), he is and you should keep an eye out for his posts.
Martin is Strategy VP for AppSense. I and others have been saying for a while that user environment virtualisation is the final piece of the virtualisation pie to fully realise statelessness, and let me tell you now there is no better product on the market for this than Environment Manager. No I'm not getting paid to write this, but in the name of responsible disclosure I will say we have a long standing and excellent relationship with AppSense at the place I work. We have stacked them up against their competitors many times over the years and on the technical / feature side they have blown the competition away every time. They are the VMware of the user environment virtualisation space.
So welcome to the blogosphere Martin, and to make up for you not telling me about the blogging I'll be expecting a ticket to get onboard the AppSense yacht at VMworld Europe 2009 :-D. And while I'm here, shout outs to Sheps and 6 figures at AppSense.
Martin is Strategy VP for AppSense. I and others have been saying for a while that user environment virtualisation is the final piece of the virtualisation pie to fully realise statelessness, and let me tell you now there is no better product on the market for this than Environment Manager. No I'm not getting paid to write this, but in the name of responsible disclosure I will say we have a long standing and excellent relationship with AppSense at the place I work. We have stacked them up against their competitors many times over the years and on the technical / feature side they have blown the competition away every time. They are the VMware of the user environment virtualisation space.
So welcome to the blogosphere Martin, and to make up for you not telling me about the blogging I'll be expecting a ticket to get onboard the AppSense yacht at VMworld Europe 2009 :-D. And while I'm here, shout outs to Sheps and 6 figures at AppSense.
Wednesday 10 December 2008
ESXi 3 Update 3 - Free Version Unshackled, hoo-rah!
I'm not going to try and claim credit for this development, but Rich Brambley (the only blog with a description that I feel outshines my own :-) broke the news today that the free version ESXi 3 Update 3 appears to have a fully functional API. I plan on testing this out tomorrow, and will report back as I'm sure others will too!
UPDATE The great Mike D has beaten me to it. Looks like all systems are go for the evolution of statelesx... ;-)
UPDATE 2 Oh man... who the !#$% is running QA in VMware? What a shocker!
UPDATE The great Mike D has beaten me to it. Looks like all systems are go for the evolution of statelesx... ;-)
UPDATE 2 Oh man... who the !#$% is running QA in VMware? What a shocker!
VMware View - Linked Clones Not A Panacea for VDI Storage Pain!
Why do I always seem to be the bad guy. I know the other guys dont gloss over the limitations or realities of product features on purpose, but sheesh it always seems to be me cutting a swathe of destruction through the marketing hype. Somehow I don't think I will be in contention for VVP status anytime soon (I'm sure the profanity doesn't help either but... fuck it. Hey it's not like kids read this, and I'm certainly not out there doing this kind of thing).
As any reader of this blog will be aware, VMware View was launched a week or so ago. Amongst it's many touted features was the oft requested "linked clone" functionality, designed to reduce the storage overheads associated with VDI. But it may not be the panacea it's being made out to be.
My 2 main concerns are:
1) Snapshots can grow up to the same size as the source disk. Although this situation will probably not be too common, you can bet your life that they will grow to the size of the free space in the base image in a manner of weeks. I've spent an _extensive_ amount of time testing this stuff out to try and battle the VDI storage cost problem. But no matter how much you tune the guest OS, there's just no way to overcome the fact that the NTFS filesystem will _always_ write to available zero'ed blocks before it writes to blocks containing deleted files. This means if you have 10GB free space, and you create and delete a 1GB file 10 times, you will end up with no net change in used storage within the guest however your snapshot will now be 10GB in size. Don't belive me? Try it yourself. Now users creating and deleting large files in this manner may again be uncommon, but temporary internet files, software distribution / patching application caches, patch uninstall directories, AV caches and definition files, temporary office files... these things all add up. Fast. Now of course each environment will differ in this regard, so the best thing you can do to get an idea of what the storage savings you can expect is take a fresh VDI machine, snapshot it, and then use it normally for a month. Of if you think you're not the average user, pick a newly provisioned user VDI machine and do the test. Monitor the growth of that snap file weekly. I think you'll be surprised at what you find. Linked clones are just snapshots at the end of the day, they don't do anything tricky with deduplication, they don't do anything tricky in the guest filesystem, they are just snapshots. Which leads me to my next major concern.
2) LUN locking. We all know that a lock is acquired on a VMFS volume whenever volume metadata is updated. Metadata updates occur everytime a snapshot file is incremented, at the moment this is hardcoded to 16MB increments. For this reason, the recommendation from VMware has always been to minimise the number of snapshotted machines on a single LUN. Something like 8 per LUN I think was the ballpark maximum. Now if the whole point of linked clones is to reduce storage, it's fair to assume you'd be planning to increase the number of VM's per LUN, not decrease them. In which case houston, we may have a problem. Perhaps linked clones increment in blocks of greater than 16MB, which may go some way towards solving the problem. But at this time I don't know if that's the case or not. Someone feel free to check this out and let me know (Rod, I'm looking at you :-)
Now of course there are many other design considerations, such having a single small LUN for the master image and partitioning your array cache so that LUN is _always_ cached. It's a snap'ed vmdk and therefore read only so this won't be a problem. Unless you dont have enough array cache to do this (which will likely be the case outside of large enterprises, or even within them in some cases).
In my mind, the real panacea for the storage problem is statelessness. User environment virtualisation / streaming and app virtualisation / streaming are going to make the biggest dent in the storage footprint, while at the same time allowing us to use much cheaper storage because when the machine state is empty until a user logs on, it doesn't matter so much if the storage containing 50 base VM images disappears (assuming you catered for this scenario, which you did because you know that cheaper disk normally means increased failure rate).
So by all means, check View out. If high latency isn't a problem for you, there's little reason to choose another broker (aside from cost of course). But don't offset the cost of the broker with promises of massive storage cost reduction without trying out my snap experiment in your environment first, or you may get burnt.
UPDATE Rod has a great post detailing his thoughts on this. Go read it!
UPDATE 2 Another excellent post on this topic from the man himself, Chad Sakac. Chad removes any fears regarding LUN locking, which IMHO is only possible with empricial testing, which is exactly what Chad and his team have done. Excellent work, and thankyou. With regards to my other concern of snapshot growth and the reality of regular snapshot reversion, he also clarifies the absolutely vital point in all of this, which I didn't do a very good job of in my initial post - every environment will differ. Although I still believe the place I work is fairly typical of any large enterprise at this point in time, the absolute best thing for you to do in your shop is test it and see what the business are willing to except in terms of rebuiilds or investment in other technologies such as app virtualisation and profile management. They may or may not offset any storage cost reductions, again every place will differ.
As any reader of this blog will be aware, VMware View was launched a week or so ago. Amongst it's many touted features was the oft requested "linked clone" functionality, designed to reduce the storage overheads associated with VDI. But it may not be the panacea it's being made out to be.
My 2 main concerns are:
1) Snapshots can grow up to the same size as the source disk. Although this situation will probably not be too common, you can bet your life that they will grow to the size of the free space in the base image in a manner of weeks. I've spent an _extensive_ amount of time testing this stuff out to try and battle the VDI storage cost problem. But no matter how much you tune the guest OS, there's just no way to overcome the fact that the NTFS filesystem will _always_ write to available zero'ed blocks before it writes to blocks containing deleted files. This means if you have 10GB free space, and you create and delete a 1GB file 10 times, you will end up with no net change in used storage within the guest however your snapshot will now be 10GB in size. Don't belive me? Try it yourself. Now users creating and deleting large files in this manner may again be uncommon, but temporary internet files, software distribution / patching application caches, patch uninstall directories, AV caches and definition files, temporary office files... these things all add up. Fast. Now of course each environment will differ in this regard, so the best thing you can do to get an idea of what the storage savings you can expect is take a fresh VDI machine, snapshot it, and then use it normally for a month. Of if you think you're not the average user, pick a newly provisioned user VDI machine and do the test. Monitor the growth of that snap file weekly. I think you'll be surprised at what you find. Linked clones are just snapshots at the end of the day, they don't do anything tricky with deduplication, they don't do anything tricky in the guest filesystem, they are just snapshots. Which leads me to my next major concern.
2) LUN locking. We all know that a lock is acquired on a VMFS volume whenever volume metadata is updated. Metadata updates occur everytime a snapshot file is incremented, at the moment this is hardcoded to 16MB increments. For this reason, the recommendation from VMware has always been to minimise the number of snapshotted machines on a single LUN. Something like 8 per LUN I think was the ballpark maximum. Now if the whole point of linked clones is to reduce storage, it's fair to assume you'd be planning to increase the number of VM's per LUN, not decrease them. In which case houston, we may have a problem. Perhaps linked clones increment in blocks of greater than 16MB, which may go some way towards solving the problem. But at this time I don't know if that's the case or not. Someone feel free to check this out and let me know (Rod, I'm looking at you :-)
Now of course there are many other design considerations, such having a single small LUN for the master image and partitioning your array cache so that LUN is _always_ cached. It's a snap'ed vmdk and therefore read only so this won't be a problem. Unless you dont have enough array cache to do this (which will likely be the case outside of large enterprises, or even within them in some cases).
In my mind, the real panacea for the storage problem is statelessness. User environment virtualisation / streaming and app virtualisation / streaming are going to make the biggest dent in the storage footprint, while at the same time allowing us to use much cheaper storage because when the machine state is empty until a user logs on, it doesn't matter so much if the storage containing 50 base VM images disappears (assuming you catered for this scenario, which you did because you know that cheaper disk normally means increased failure rate).
So by all means, check View out. If high latency isn't a problem for you, there's little reason to choose another broker (aside from cost of course). But don't offset the cost of the broker with promises of massive storage cost reduction without trying out my snap experiment in your environment first, or you may get burnt.
UPDATE Rod has a great post detailing his thoughts on this. Go read it!
UPDATE 2 Another excellent post on this topic from the man himself, Chad Sakac. Chad removes any fears regarding LUN locking, which IMHO is only possible with empricial testing, which is exactly what Chad and his team have done. Excellent work, and thankyou. With regards to my other concern of snapshot growth and the reality of regular snapshot reversion, he also clarifies the absolutely vital point in all of this, which I didn't do a very good job of in my initial post - every environment will differ. Although I still believe the place I work is fairly typical of any large enterprise at this point in time, the absolute best thing for you to do in your shop is test it and see what the business are willing to except in terms of rebuiilds or investment in other technologies such as app virtualisation and profile management. They may or may not offset any storage cost reductions, again every place will differ.
Sunday 7 December 2008
Why Times Like These are _Great_ for Enterprise IT
First, my heart goes out to out to all those who have found themselves out of a job during these dark financial times. I hope you won't find this post antagonistic in any way, it is obviously written from the perspective of someone who is still gainfully employed in a large enterprise (but what the future holds is anyone's guess). If you are in a tight situation right now, I can only hope that this post will give you some ammunition for your next interview, or help give some focus to your time between jobs.
OK, I'll lighten up a little now :-). So the title of this post may seem a little odd. All we seem to be hearing about these days is lay offs and cutbacks. I know of several institutions who have mandated all contractors to not be renewed, and others who are chopping full time staff alongside contractors. Either way, doesn't sound too great at all, and in fact I'm beginning to think I may change that title.
But then I remember what's great about restriction - it's a lightning rod for innovation. Look at all the success stories on the web - the vast majority of them were born from tight circumstances, from the poor student to the unemployed developer. And if you're on top of your game in the enterprise, it's no different - you can write your own internal success story.
Some of the things I hear around my office are no doubt typical of any architecture & engineering group in a large investment bank. The focus from on high is on keeping the lights on, and cutting costs at any available opportunity. But what's maybe different is the approach to cost cutting, which is absolutely grounded in fundamental mathematical principles. What do I mean by that? If you need to spend $1 to save $2, then you're still saving $1 so it's worth doing.
But why would you need financial dire straits for such behaviour? Surely you would follow the same principles in the good times as well as bad? Damn straight we do - the difference is in these times, _everything_ can be challenged. And when you can challenge everything, you can innovate like an engineer possessed.
Case in point, clouds. And let's be honest, there's only one viable player in the market currently, Amazon. And boy are the eyes of the business on them. But what's been lacking until now is the ability for an internal cloud to compete with them on purely a cost basis. Amazon's EC2 pricing includes a bucket of compute resources, SLA's for those compute resources, and a choice of preconfigured AMI's (I'm conveniently ignoring the ability to roll your own AMI and upload it, for the time being).
Here's what Amazon's pricing doesn't include. Guest support, backup, monitoring, antivirus, patching, and auditing. Where is the greatest cost associated with enterprise compute resources? Those very same things.
Now, yes I am conveniently ignoring the ability to roll your own AMI and upload it to EC2, but even if you did include all the aforementioned agents in your image, how practical would that actually be? I have yet to see an enterprise with a monitoring system that was intelligent enough to know the difference between "down because someone shut me down because they don't need me right now" and "down because of a hardware / software error". So if, in order to get Amazon's cheap pricing, we're willing to forgo monitoring within the guest, then surely I can do the same for my internal cloud machines? And the same goes for backup. Machines on a backup schedule don't only attract backup software licensing costs, there is monitoring overheads, and storage costs associated with the backed up data. And again, backup systems are generally inflexible. A backup missed is a backup missed, and generally the operational decree will be that it needs to be run at the first opportunity. But in order to get Amazon's cheap pricing (there's additional charges for network IO), we're willing to forgo backups. Hey, there's another cost I can strike off the list for my internal cloud offering! How about authentication? Domain membership has all sorts of implications for creation / deletion / archiving or machines, snapshots that get rolled back beyond 30 days etc. Windows based EC2 machines with "authentication services" attract something like a 50% premium. Perhaps my internal cloud machines should too. After all, does every development box _really_ need to be on the domain? How about grid nodes?
I won't bore with going through the rest of the list, but you get the picture. In order to get this rock bottom pricing, there is a _lot_ of functionality that is generally taken for granted in the enterprise that needs to be stripped out.
One of the biggest challenges in the enterprise is reworking the charging model to strip out all these things that now look like "extras" in comparison to Amazon's EC2. And this is where the "great times for enterprise computing" comes into the picture - it's about time these things were fucking well treated as extras, and that an _accurate_ pricing model was available for the business that broke down all these costs, and made them optional. That's the only way we'll get an apples to apples comparison to the likes of EC2.
And you know what? It's actually happening where I work. All the restrictions that would've hamstrung us from ever offering something on par with EC2 are being lifted. Finally, cheap utility _compute_ (I can't stress that enough - COMPUTE) is something we're actually going to be able to offer for the first time ever. And it's all thanks to the financial crisis, because the laser like focus on cost would never have happened otherwise.
This of course also has implications for VMware. When I say _everything_ can be challenged, I mean _everything_. Would it be cheaper for us to pay for VMware, or for someone like me to be given a few internal developers and infrastructure resources and take a shot at building something like EC2, right down to the Xen part of things?
Right now in many companies, it's survival of the fittest. If all we're going to be left with internally is a skeletal staff of absolute guns in their respective fields, along with a mandate to drive down costs through innovation and to hell with how things used to be done, then you can bet your bottom dollar something like that is entirely possible.
So if you do find yourself out of work, maybe it's time to further develop those automation skills. Get familiar with web services, pick any language you like - C#, Java, Python etc. PowerShell is a great option too, check out the PowerShell 2.0 CTP. Sign up for an Amazon Web Services account and figure out how to do stuff (you only pay for what you use, it can be cheap). Think about what they offer, find the strengths and the weaknesses, and then think about you might implement something similar in an enterprise, and what would be required to do it better. Think about how you might burst into something like EC2 from an internal cloud. What layers need to be loosely coupled in order to do such a thing in the most efficient way? What implications do external clouds have for internal cloud architecture and operations? Now take all that, and expand your scope to Google's cloud offering, what's coming with Azure, what other players there are in the field.
Yes sir, exciting times ahead in the next few years, even moreso than they were before the financial meltdown occurred.
OK, I'll lighten up a little now :-). So the title of this post may seem a little odd. All we seem to be hearing about these days is lay offs and cutbacks. I know of several institutions who have mandated all contractors to not be renewed, and others who are chopping full time staff alongside contractors. Either way, doesn't sound too great at all, and in fact I'm beginning to think I may change that title.
But then I remember what's great about restriction - it's a lightning rod for innovation. Look at all the success stories on the web - the vast majority of them were born from tight circumstances, from the poor student to the unemployed developer. And if you're on top of your game in the enterprise, it's no different - you can write your own internal success story.
Some of the things I hear around my office are no doubt typical of any architecture & engineering group in a large investment bank. The focus from on high is on keeping the lights on, and cutting costs at any available opportunity. But what's maybe different is the approach to cost cutting, which is absolutely grounded in fundamental mathematical principles. What do I mean by that? If you need to spend $1 to save $2, then you're still saving $1 so it's worth doing.
But why would you need financial dire straits for such behaviour? Surely you would follow the same principles in the good times as well as bad? Damn straight we do - the difference is in these times, _everything_ can be challenged. And when you can challenge everything, you can innovate like an engineer possessed.
Case in point, clouds. And let's be honest, there's only one viable player in the market currently, Amazon. And boy are the eyes of the business on them. But what's been lacking until now is the ability for an internal cloud to compete with them on purely a cost basis. Amazon's EC2 pricing includes a bucket of compute resources, SLA's for those compute resources, and a choice of preconfigured AMI's (I'm conveniently ignoring the ability to roll your own AMI and upload it, for the time being).
Here's what Amazon's pricing doesn't include. Guest support, backup, monitoring, antivirus, patching, and auditing. Where is the greatest cost associated with enterprise compute resources? Those very same things.
Now, yes I am conveniently ignoring the ability to roll your own AMI and upload it to EC2, but even if you did include all the aforementioned agents in your image, how practical would that actually be? I have yet to see an enterprise with a monitoring system that was intelligent enough to know the difference between "down because someone shut me down because they don't need me right now" and "down because of a hardware / software error". So if, in order to get Amazon's cheap pricing, we're willing to forgo monitoring within the guest, then surely I can do the same for my internal cloud machines? And the same goes for backup. Machines on a backup schedule don't only attract backup software licensing costs, there is monitoring overheads, and storage costs associated with the backed up data. And again, backup systems are generally inflexible. A backup missed is a backup missed, and generally the operational decree will be that it needs to be run at the first opportunity. But in order to get Amazon's cheap pricing (there's additional charges for network IO), we're willing to forgo backups. Hey, there's another cost I can strike off the list for my internal cloud offering! How about authentication? Domain membership has all sorts of implications for creation / deletion / archiving or machines, snapshots that get rolled back beyond 30 days etc. Windows based EC2 machines with "authentication services" attract something like a 50% premium. Perhaps my internal cloud machines should too. After all, does every development box _really_ need to be on the domain? How about grid nodes?
I won't bore with going through the rest of the list, but you get the picture. In order to get this rock bottom pricing, there is a _lot_ of functionality that is generally taken for granted in the enterprise that needs to be stripped out.
One of the biggest challenges in the enterprise is reworking the charging model to strip out all these things that now look like "extras" in comparison to Amazon's EC2. And this is where the "great times for enterprise computing" comes into the picture - it's about time these things were fucking well treated as extras, and that an _accurate_ pricing model was available for the business that broke down all these costs, and made them optional. That's the only way we'll get an apples to apples comparison to the likes of EC2.
And you know what? It's actually happening where I work. All the restrictions that would've hamstrung us from ever offering something on par with EC2 are being lifted. Finally, cheap utility _compute_ (I can't stress that enough - COMPUTE) is something we're actually going to be able to offer for the first time ever. And it's all thanks to the financial crisis, because the laser like focus on cost would never have happened otherwise.
This of course also has implications for VMware. When I say _everything_ can be challenged, I mean _everything_. Would it be cheaper for us to pay for VMware, or for someone like me to be given a few internal developers and infrastructure resources and take a shot at building something like EC2, right down to the Xen part of things?
Right now in many companies, it's survival of the fittest. If all we're going to be left with internally is a skeletal staff of absolute guns in their respective fields, along with a mandate to drive down costs through innovation and to hell with how things used to be done, then you can bet your bottom dollar something like that is entirely possible.
So if you do find yourself out of work, maybe it's time to further develop those automation skills. Get familiar with web services, pick any language you like - C#, Java, Python etc. PowerShell is a great option too, check out the PowerShell 2.0 CTP. Sign up for an Amazon Web Services account and figure out how to do stuff (you only pay for what you use, it can be cheap). Think about what they offer, find the strengths and the weaknesses, and then think about you might implement something similar in an enterprise, and what would be required to do it better. Think about how you might burst into something like EC2 from an internal cloud. What layers need to be loosely coupled in order to do such a thing in the most efficient way? What implications do external clouds have for internal cloud architecture and operations? Now take all that, and expand your scope to Google's cloud offering, what's coming with Azure, what other players there are in the field.
Yes sir, exciting times ahead in the next few years, even moreso than they were before the financial meltdown occurred.
Thursday 4 December 2008
ThinApp Blog - would you like a glass of water to help swallow that foot?
I'm going to try and resist the urge to make this post another 'effenheimer' (as Mr Boche might say :-) but my mind boggles as to WTF the ThinApp team were thinking when they made this post. Way to call out a major shortcoming of your own product guys! To be honest, I'm completely amazed that VMware don't support their own client as a ThinApp Package. Say what you will about Microsoft, but you gotta respect their 'eat our own dogfood' mentality. To my knowledge, if you encounter an issue with any Microsoft client based app that is delivered via App-V, they will support you to the hilt.
Now that i've passed the Planet v12n summary wordcount, I can give in to my temptation and start dropping the F bombs, because I'm mad. The VI client is a fairly typical .NET based app. If VMware themselves don't support ThinApp'ing it, how the fuck do they expect other ISV's with .NET based products to support ThinApp'ing their apps? Imagine if VMware said that running vCenter in a guest wasn't supported - what kind of message would that send about machine virtualisation! Adding to the embarrassment, it seems that ThinApp'ing the .NET Framework itself is no dramas!!!
It's laughable that a company would spend so much time and money on marketing efforts like renaming products mid-lifecycle, but let stuff like this slip by the wayside. Let's hope this is fixed for the next version of VI.
Now that i've passed the Planet v12n summary wordcount, I can give in to my temptation and start dropping the F bombs, because I'm mad. The VI client is a fairly typical .NET based app. If VMware themselves don't support ThinApp'ing it, how the fuck do they expect other ISV's with .NET based products to support ThinApp'ing their apps? Imagine if VMware said that running vCenter in a guest wasn't supported - what kind of message would that send about machine virtualisation! Adding to the embarrassment, it seems that ThinApp'ing the .NET Framework itself is no dramas!!!
It's laughable that a company would spend so much time and money on marketing efforts like renaming products mid-lifecycle, but let stuff like this slip by the wayside. Let's hope this is fixed for the next version of VI.
Wednesday 3 December 2008
HA Slot Size Calculations in the Absence of Resource Reservations
Ahhh, the ol' HA slot size calculations. Many a post has been written, many a document published that tried to explain just how HA slot sizes are calculated. But the one thing missing from most of these, certainly from the VMware documentation, is what behaviour can be expected when there are no resource reservations on an individual VM. For example in many large scale VDI deployments that I know of, share based resource pools are used to assert VM priority rather than resource reservations being set per-VM.
So here's the rub.
In the absence of any VM resource reservations, HA calculates the slot size based on a _minimum_ of 256MHz CPU and 256MB RAM. The RAM amount varies however, not by something intelligent like average guest memory allocation or average guest memory usage, but by the table on page 136 / 137 of the resource management guide, which is the memory overhead associated with guests depending on how much allocated memory the guest has, how many vCPU's the guest has, and what the vCPU architecture is. So lets be straight on this. If 256MB > 'VM memory overhead', then 256MB is what HA uses for the slot size calculation. If 'VM memory overhead' > 256MB, then 'VM memory overhead' is what is used for the slot size calculation.
So for example, a cluster full of single vCPU 32bit Windows XP VM's will have the default HA slot size of 256MHz / 256MB RAM in the absence of any VM resource reservations. Net result? A cluster of 8 identical hosts, each with 21GHz CPU and 32GB RAM, and HA configured for 1 host failure, will result in HA thinking it can safely run something like 7 x (21GHz / 256MHz) guests in the cluster!!!
Which led to a situation I came across recently whereby HA thought it still had 4 hosts worth of failover capacity in an 8 host cluster with over 300 VM's running on it, even though the average cluster memory utilisation was close to 90%. Clearly, a single host failure would impact this cluster, let alone 4 host failures. 80-90% resource utilisation in the cluster is a pretty sweet spot imho, the question is simply do you want that kind of utilisation under normal operating conditions, or under failure conditions. As an architect, I should not be making that call - the business owners of the platform should be making that call. In these dark financial times, I'm sure you can guess what they'll opt for. But the bottom line is the business signs off on the risk acceptance - not me, and certainly not the support organisation. But I digress...
I hope HA can become more intelligent in how it calculates slot sizes in the future. Giving us the das.vmMemoryMinMB and das.vmCpuMinMHz advanced HA settings in vCenter 2.5 was a start, something more fluid would be most welcome.
PS. I'd like to thank a certain VMware TAM who is assigned to the account of a certain tier 1 global investment bank that employs a certain blogger, for helping to shed light on this information. You know who you are ;-)
So here's the rub.
In the absence of any VM resource reservations, HA calculates the slot size based on a _minimum_ of 256MHz CPU and 256MB RAM. The RAM amount varies however, not by something intelligent like average guest memory allocation or average guest memory usage, but by the table on page 136 / 137 of the resource management guide, which is the memory overhead associated with guests depending on how much allocated memory the guest has, how many vCPU's the guest has, and what the vCPU architecture is. So lets be straight on this. If 256MB > 'VM memory overhead', then 256MB is what HA uses for the slot size calculation. If 'VM memory overhead' > 256MB, then 'VM memory overhead' is what is used for the slot size calculation.
So for example, a cluster full of single vCPU 32bit Windows XP VM's will have the default HA slot size of 256MHz / 256MB RAM in the absence of any VM resource reservations. Net result? A cluster of 8 identical hosts, each with 21GHz CPU and 32GB RAM, and HA configured for 1 host failure, will result in HA thinking it can safely run something like 7 x (21GHz / 256MHz) guests in the cluster!!!
Which led to a situation I came across recently whereby HA thought it still had 4 hosts worth of failover capacity in an 8 host cluster with over 300 VM's running on it, even though the average cluster memory utilisation was close to 90%. Clearly, a single host failure would impact this cluster, let alone 4 host failures. 80-90% resource utilisation in the cluster is a pretty sweet spot imho, the question is simply do you want that kind of utilisation under normal operating conditions, or under failure conditions. As an architect, I should not be making that call - the business owners of the platform should be making that call. In these dark financial times, I'm sure you can guess what they'll opt for. But the bottom line is the business signs off on the risk acceptance - not me, and certainly not the support organisation. But I digress...
I hope HA can become more intelligent in how it calculates slot sizes in the future. Giving us the das.vmMemoryMinMB and das.vmCpuMinMHz advanced HA settings in vCenter 2.5 was a start, something more fluid would be most welcome.
PS. I'd like to thank a certain VMware TAM who is assigned to the account of a certain tier 1 global investment bank that employs a certain blogger, for helping to shed light on this information. You know who you are ;-)
Thursday 27 November 2008
Microsoft Offline Virtual Machine Servicing Tool 2.0
This one seems to have slipped by like a Vaseline coated ninja. Microsoft have released the long awaited version 2.0 of their Offline Virtual Machine Servicing Tool (jokes ppl, jokes).
Seriously though, what impresses me the most about this tool is it's size, which is only a few MB - it's little more than a bunch of scripts cobbled together with a UI. Makes one wonder how easily it could be hacked to work with vCenter and WSUS... hmmmm...
Seriously though, what impresses me the most about this tool is it's size, which is only a few MB - it's little more than a bunch of scripts cobbled together with a UI. Makes one wonder how easily it could be hacked to work with vCenter and WSUS... hmmmm...
Wednesday 26 November 2008
HA Allows Cake for All? No Wonder I'm Overwieght!
I've got a cake. It's my favourite variety, caramel mud. As much as I'd like to eat the whole cake myself, in a shameless attempt to increase my blog audience I'm going to eat half and give half to the first person to email me after reading this post*.
Question: How much cake is left for the second person to email me after reading this post?
None. That's right, I ate half and gave the other half to the first mailer.
But if I was HA configured to allow a single host failure, some recently observed behaviour indicates that the first mailer would actually only get 1/4 of the cake, and there would be some cake left for every person who mailed me until infinity. This is because HA doesn't appear to have any concept of a 'known good state' - instead, it seems that if a single host fails (half cake eaten by me), it then re-evaluates the cluster size (the half cake left is now considered the whole cake) and adjusts it's resource cap to allow for another single host to fail (first mailer takes half of the new cake size, the cake size is recalculated, next mailer gets half the new cake size, the cake size is recalculated, ad infinitum).
In my mind, this behaviour is not correct. If I tell HA I want to allow for a single host failure, then it should have some idea of what my known good state is. When one host actually does fail, then my risk criterion has been met and all resource guarantees in the event of a subsequent host failure are off. But it seems that all HA knows is how many hosts are in a cluster at any point in time, and how many failures to allow for at any point in time. This obviously has some implications for cluster design, in particular the "do not allow violation of availability constraints" option. Previously I was a strong advocate of taking this option - in the enterprise, soft limits are hardly ever honoured. But now I'm looking at using a "master" resource pool to achieve my resource constraint and switching to the other option.
I'm hoping the first person to mail me after reading this will be Duncan or Mike telling me I don't know wtf I'm talking about, but I've come to this belief after some conversations with VMware during a post mortem of a production incident so I'm not entirely to blame if I'm wrong :-P. If anyone else out there has seen similar behaviour, email me now - that half-a-cake could be yours!
*The cake is a lie.
Question: How much cake is left for the second person to email me after reading this post?
None. That's right, I ate half and gave the other half to the first mailer.
But if I was HA configured to allow a single host failure, some recently observed behaviour indicates that the first mailer would actually only get 1/4 of the cake, and there would be some cake left for every person who mailed me until infinity. This is because HA doesn't appear to have any concept of a 'known good state' - instead, it seems that if a single host fails (half cake eaten by me), it then re-evaluates the cluster size (the half cake left is now considered the whole cake) and adjusts it's resource cap to allow for another single host to fail (first mailer takes half of the new cake size, the cake size is recalculated, next mailer gets half the new cake size, the cake size is recalculated, ad infinitum).
In my mind, this behaviour is not correct. If I tell HA I want to allow for a single host failure, then it should have some idea of what my known good state is. When one host actually does fail, then my risk criterion has been met and all resource guarantees in the event of a subsequent host failure are off. But it seems that all HA knows is how many hosts are in a cluster at any point in time, and how many failures to allow for at any point in time. This obviously has some implications for cluster design, in particular the "do not allow violation of availability constraints" option. Previously I was a strong advocate of taking this option - in the enterprise, soft limits are hardly ever honoured. But now I'm looking at using a "master" resource pool to achieve my resource constraint and switching to the other option.
I'm hoping the first person to mail me after reading this will be Duncan or Mike telling me I don't know wtf I'm talking about, but I've come to this belief after some conversations with VMware during a post mortem of a production incident so I'm not entirely to blame if I'm wrong :-P. If anyone else out there has seen similar behaviour, email me now - that half-a-cake could be yours!
*The cake is a lie.
Thursday 20 November 2008
Symantec reverts to normal, well done. And well done community!
Unfortunately I couldn't break the news when I heard it as I was at work (no way I'm blogging from there, my boss reads this - hi Mark :D), but Symantec has updated the original KB article to something much, much more reasonable (although it seems to be offline at the minute).
No company is immune from the odd premature / alarmist KB article, and however this happened doesn't matter as much as the outcome. I'm sure a lot was going on behind the scenes before I broke the news, but still I'd like to think we all played some part in getting it cleared up so quickly. Power to the people :-)
No company is immune from the odd premature / alarmist KB article, and however this happened doesn't matter as much as the outcome. I'm sure a lot was going on behind the scenes before I broke the news, but still I'd like to think we all played some part in getting it cleared up so quickly. Power to the people :-)
Tuesday 18 November 2008
Symantec Does _NOT_ Support Vmotion... WTF!?!?!
Make sure you're sitting down before reading this Symantec KB article which is only 1 month old and clearly states they do _not_ support any current version of their product on ESX if Vmotion is enabled. No, it's not a joke.
It's a _fucking_ joke. Symantec have essentially pulled together a list of random issues that are almost certainly intermittent in nature and could have a near infinite number of causes, and somehow slapped the blame on Vmotion without as much as a single word of how they arrived at this conclusion. When Microsoft shut the AV vendors out of the Vista kernel, I actually felt a little sympathy for them (the AV vendors). But after reading this, I can't imagine the bullshit Microsoft must have had to put up with over the years. It's no wonder Microsoft tried to do their own thing with AV.
I urge every enterprise on the planet who are customers of both VMware and Symantec to rain fire and brimstone upon Symantec (I've already started), because your entire server and VDI infrastructure is at this time officially unsupported. The VMware vendor relationship team have already kicked into gear, we need to raise some serious hell as customers to drive this point home, and hard.
This is absolutely disgraceful and must not stand.
UPDATE The original KB article as been updated, support has been restored to normal!
It's a _fucking_ joke. Symantec have essentially pulled together a list of random issues that are almost certainly intermittent in nature and could have a near infinite number of causes, and somehow slapped the blame on Vmotion without as much as a single word of how they arrived at this conclusion. When Microsoft shut the AV vendors out of the Vista kernel, I actually felt a little sympathy for them (the AV vendors). But after reading this, I can't imagine the bullshit Microsoft must have had to put up with over the years. It's no wonder Microsoft tried to do their own thing with AV.
I urge every enterprise on the planet who are customers of both VMware and Symantec to rain fire and brimstone upon Symantec (I've already started), because your entire server and VDI infrastructure is at this time officially unsupported. The VMware vendor relationship team have already kicked into gear, we need to raise some serious hell as customers to drive this point home, and hard.
This is absolutely disgraceful and must not stand.
UPDATE The original KB article as been updated, support has been restored to normal!
Monday 17 November 2008
Microsoft Azure Infrastructure Deployment Video
I've been a bit quiet of late, mainly due to the digestion of Microsoft's PDC 2008 content (what a great idea to provide the content for free after the conference - VMware could take a leaf out of that book). I meant to post this up yesterday as another SAAAP installment but missed the deadline... but what the hell, I'll tag this post anyway!
One of the more infrastructure oriented PDC sessions was "Under the Hood - Inside the Windows Azure Hosting Environment". Skip forward to around 43 minutes into the presentation, where Chuck Lenzmeier goes into the deployment model used within the Azure cloud (you can stop watching at around 48 minutes).
Conceptually, this is _exactly_ the deployment model I and ppl like Lance Berc envisage for ESXi. Rather than put that base VHD onto local USB devices ala ESXi, Microsoft PXE boot a Windows PE "maintenance os", drop a common base image onto the endpoint, dynamically build a personality (offline) as a differencing disk (ie linked clone), drop that down to the endpoint, and then boot straight off the differencing disk VHD (booting directly off VHD's is a _very_ cool feature of Win7 / Server 2008 R2). I'm glad even Microsoft recognise the massive benefits of this approach - no installation, rapid rollback, etc.
Now ESXi of course has one *massive* advantage over Windows in this scenario - it is weighs in at around the same size as a typical Windows PE build, much smaller than a Hyper-V enabled Server Core build.
And if only VMware would support PXE booting ESXi, you could couple it with Lance's birth client and midwife or our statelesx, and you don't even need the 'maintenance OS'. You get an environment that is almost identical conceptually, but can be deployed much much faster due to the ~150MB or so total size of ESXi (including Windows, Linux and Solaris vmtools iso's and customised configuration to enable kernel mode options like swap or LVM.EnableResignature within ESXi that would otherwise require a reboot (chicken, meet egg :-)) versus near a GB of Windows PE and Hyper-V with Server Core. Of course I don't even need to go into the superiority of ESXi over Hyper-V ;-)
With Windows Server 2008 R2 earmarked for a 2010 release, it will be sometime before the sweet deployment scenario outlined in that video is available to Microsoft customers (gotta love how Microsoft get the good stuff to themselves first - jeez, what a convenient way to ensure your cloud service is much more efficient than anything your customer could build with your own technology). But by that time they will have a helluva set of best practice deployment knowledge for liquid infrastructure like this, and you can bet aspects of their "fabric controller" will find their way into the System Center management suite.
The liquid compute deployment gauntlet has been thrown VMware, time to step up to the plate.
One of the more infrastructure oriented PDC sessions was "Under the Hood - Inside the Windows Azure Hosting Environment". Skip forward to around 43 minutes into the presentation, where Chuck Lenzmeier goes into the deployment model used within the Azure cloud (you can stop watching at around 48 minutes).
Conceptually, this is _exactly_ the deployment model I and ppl like Lance Berc envisage for ESXi. Rather than put that base VHD onto local USB devices ala ESXi, Microsoft PXE boot a Windows PE "maintenance os", drop a common base image onto the endpoint, dynamically build a personality (offline) as a differencing disk (ie linked clone), drop that down to the endpoint, and then boot straight off the differencing disk VHD (booting directly off VHD's is a _very_ cool feature of Win7 / Server 2008 R2). I'm glad even Microsoft recognise the massive benefits of this approach - no installation, rapid rollback, etc.
Now ESXi of course has one *massive* advantage over Windows in this scenario - it is weighs in at around the same size as a typical Windows PE build, much smaller than a Hyper-V enabled Server Core build.
And if only VMware would support PXE booting ESXi, you could couple it with Lance's birth client and midwife or our statelesx, and you don't even need the 'maintenance OS'. You get an environment that is almost identical conceptually, but can be deployed much much faster due to the ~150MB or so total size of ESXi (including Windows, Linux and Solaris vmtools iso's and customised configuration to enable kernel mode options like swap or LVM.EnableResignature within ESXi that would otherwise require a reboot (chicken, meet egg :-)) versus near a GB of Windows PE and Hyper-V with Server Core. Of course I don't even need to go into the superiority of ESXi over Hyper-V ;-)
With Windows Server 2008 R2 earmarked for a 2010 release, it will be sometime before the sweet deployment scenario outlined in that video is available to Microsoft customers (gotta love how Microsoft get the good stuff to themselves first - jeez, what a convenient way to ensure your cloud service is much more efficient than anything your customer could build with your own technology). But by that time they will have a helluva set of best practice deployment knowledge for liquid infrastructure like this, and you can bet aspects of their "fabric controller" will find their way into the System Center management suite.
The liquid compute deployment gauntlet has been thrown VMware, time to step up to the plate.
Sunday 9 November 2008
VMware: Unshackle ESXi, or Follow Microsoft Into the Cloud...
One of the things that will be interesting to observe as the cloud matures will the influence the internal and external clouds will have on each on each other.
To this end, I think Microsoft have benefited from years of experience with the web hosting industry, and as a result have completely nailed the correct approach for them to take into the cloud. VMware doesn't have the benefit of this experience, and should watch Microsoft closely as the key to their strategy has more in common with what VMware needs to be successful than one might think. That key being cost.
For years, Microsoft never made a dent in the web hosting space. It would be naive to attribute this solely to the stability and security of the platform - IIS 5 had a few howlers sure, but so has Apache over the same time. IIS 6 however was entirely different - in it's default configuration, not a single remotely exploitable vulnerability has been publicly identified to date. But there was the cost angle - Windows based hosting charges were far greater than comparable Linux based offerings, and they pretty much stayed that way until SWsoft came along with Virtuozzo for Windows in 2005. The massive advantage Virtuozzo had (and still has) over other Virtualisation offerings from a cost perspective is that only a single Windows license is required for the base OS - all the containers running on top of that base don't cost anything more. Now all of a sudden web hosting companies could apply the same techniques to Windows as they had used for Linux based platforms for years, and achieve massive cost reductions.
I can see a similar problem for VMware in the external cloud space. Let's compare 2 companies currently offering infrastructure based cloud services - Terremark and Amazon.
Terremark's 'Infinistructure' is based (among other things) on hardware from HP, a hypervisor from VMware (although it's not clear if this is the only hypervisor available), all managed by an in house developed application called digitalOps which apparently had a developmemt cost of over $10mil USD to date.
Amazon's EC2 on the other hand uses custom built hardware from commodity components, uses the free open source Xen (and likely their own version of Linux for Dom0), and of course a fully developed management API based on open web standards.
Comparing those 2, which do you think will _always_ cost more? If VMware want to seriously compete in the external cloud space, they need to address this. Right now I see 2 options for them. One is to unshackle the free version of ESXi, so that the API is fully functional and hence 3rd parties could write their own management tools to sit on top and not have to pay for the VMware tools (and then have to write their own stuff anyway, as Terremark have done). The other is for VMware to enter the hosting space themselves, as they would be the only company in a position to avoid paying software licenses for ESX and their VI management layer.
I'm sure VMware realise they only have a limited time in which to establish themselves in this space, because 2 trends are in motion that have the potential to render the operating system insignificant, let alone the underlying hypervisor: application virtualisation, and cloud aware web based applications. But if will likely be some time before either of those 2 will be adopted broadly in the enterprise, and hence VMware are pushing the fact that their take on cloud is heavily infrastructure focused, and thus doesn't require any changes in the application layer.
Sure, unshackling free ESXi would mean missing out on some revenue from external cloud providers, but it will go a long way towards insulating them from any external cloud influence creeping into the internal cloud. What do I mean by that? Say I was a CIO, and I had 2 external cloud providers vying for my business. While they both offer identical SLA's surrounding performance and availability, one of them offers a near seamless internal/external cloud transition based on the software stack in my internal cloud. It is however 3 times the cost of the other provider. After signing a short-term agreement with the more expensive cloud provider, I would be straight on the phone to my directs asking for an investigation into the internal cloud, with a view to making it more compatible with the cheaper external offering.
Which is why Microsoft have got the play right. They know that no 3rd party host can pay for Windows and compete with Linux on price. So instead of go after it with Hyper-V on an infrastructure level, they're taking a longer term approach and going after the cloud aware web based application market. Personally, I can't ever see VMware becoming a cloud host, which means they need to do something about unshackling ESXi. And fast - the clock is ticking.
To this end, I think Microsoft have benefited from years of experience with the web hosting industry, and as a result have completely nailed the correct approach for them to take into the cloud. VMware doesn't have the benefit of this experience, and should watch Microsoft closely as the key to their strategy has more in common with what VMware needs to be successful than one might think. That key being cost.
For years, Microsoft never made a dent in the web hosting space. It would be naive to attribute this solely to the stability and security of the platform - IIS 5 had a few howlers sure, but so has Apache over the same time. IIS 6 however was entirely different - in it's default configuration, not a single remotely exploitable vulnerability has been publicly identified to date. But there was the cost angle - Windows based hosting charges were far greater than comparable Linux based offerings, and they pretty much stayed that way until SWsoft came along with Virtuozzo for Windows in 2005. The massive advantage Virtuozzo had (and still has) over other Virtualisation offerings from a cost perspective is that only a single Windows license is required for the base OS - all the containers running on top of that base don't cost anything more. Now all of a sudden web hosting companies could apply the same techniques to Windows as they had used for Linux based platforms for years, and achieve massive cost reductions.
I can see a similar problem for VMware in the external cloud space. Let's compare 2 companies currently offering infrastructure based cloud services - Terremark and Amazon.
Terremark's 'Infinistructure' is based (among other things) on hardware from HP, a hypervisor from VMware (although it's not clear if this is the only hypervisor available), all managed by an in house developed application called digitalOps which apparently had a developmemt cost of over $10mil USD to date.
Amazon's EC2 on the other hand uses custom built hardware from commodity components, uses the free open source Xen (and likely their own version of Linux for Dom0), and of course a fully developed management API based on open web standards.
Comparing those 2, which do you think will _always_ cost more? If VMware want to seriously compete in the external cloud space, they need to address this. Right now I see 2 options for them. One is to unshackle the free version of ESXi, so that the API is fully functional and hence 3rd parties could write their own management tools to sit on top and not have to pay for the VMware tools (and then have to write their own stuff anyway, as Terremark have done). The other is for VMware to enter the hosting space themselves, as they would be the only company in a position to avoid paying software licenses for ESX and their VI management layer.
I'm sure VMware realise they only have a limited time in which to establish themselves in this space, because 2 trends are in motion that have the potential to render the operating system insignificant, let alone the underlying hypervisor: application virtualisation, and cloud aware web based applications. But if will likely be some time before either of those 2 will be adopted broadly in the enterprise, and hence VMware are pushing the fact that their take on cloud is heavily infrastructure focused, and thus doesn't require any changes in the application layer.
Sure, unshackling free ESXi would mean missing out on some revenue from external cloud providers, but it will go a long way towards insulating them from any external cloud influence creeping into the internal cloud. What do I mean by that? Say I was a CIO, and I had 2 external cloud providers vying for my business. While they both offer identical SLA's surrounding performance and availability, one of them offers a near seamless internal/external cloud transition based on the software stack in my internal cloud. It is however 3 times the cost of the other provider. After signing a short-term agreement with the more expensive cloud provider, I would be straight on the phone to my directs asking for an investigation into the internal cloud, with a view to making it more compatible with the cheaper external offering.
Which is why Microsoft have got the play right. They know that no 3rd party host can pay for Windows and compete with Linux on price. So instead of go after it with Hyper-V on an infrastructure level, they're taking a longer term approach and going after the cloud aware web based application market. Personally, I can't ever see VMware becoming a cloud host, which means they need to do something about unshackling ESXi. And fast - the clock is ticking.
Thursday 30 October 2008
ESX 3.5 Update 3 Release Imminent!
It seems the ESX 3.5 Update 3 release is imminent, as per some recent updates to the VMware website (screeny below)
Wonder if we'll get any timebomb action this time :D

Wonder if we'll get any timebomb action this time :D
Monday 27 October 2008
Transcript of Best VMTN Community Roundtable Yet!
Hooo-rah! to Rod Haywood for transcribing VMTN Community Roundtable #22, which was in my mind the best roundtable yet (you got Krusty sized shoes to fill next week Chad :-). Bill Shelton was bang on point with just about everything he said. If you've spent any time with the guts of the SDK you'll know just how inconsistent it can be. In fact a while back I asked Carter and Steve how come the API was so quirky with guys like them working at VMware who clearly know better (otherwise they wouldn't have felt the need to write their respective wrappers). Their answer? "We've only been here for about a year." Bill Shelton falls into that category as well. Knowing how people think in those kinds of positions at VMware is very comforting indeed. I wonder what the Windows Azure API will look like. Actually no, I don't even care.
Sunday 26 October 2008
Clouds. Plenty of Them Around This Sunday Afternoon...
... and I'm not just talking about London. The topic of cloud or liquid or utility compute is perfectly suited for an edition of Sunday Afternoon Architecture & Philosophy.
Note that I said compute there. Indeed the cloud has many other components, but infrastructure guys like me will mainly be concerned with compute. And maybe storage. And of course what connects things to either of those 2. Hmmm. OK, maybe it's more than just compute, but for all intents and purposes I'm going to try and stay focused on compute.
So lets talk about apps. See what I did there? At the end of the day, compute is only good for one thing - running apps. But I can't see us getting to this fluffy land of external federated clouds without a fundamental change to how most applications in an enterprise environment run. Now don't get me wrong - the whole point of cloud compute from infrastructure up is that we don't have to change the apps. I get that. But in reality, they're going to have to change - they have to become portable, and any state needs to move out of the endpoint and into somewhere central. Why? Because it's gonna be a looooong time before _data_ is held in an external cloud, if ever IMHO. As Tim O'Reilly points out in his recent post Web 2.0 and Cloud Computing:
Cloud compute means exactly as the name implies. COMPUTE. As in run up a compute engine (ie. an OS + App + State stack), throw some data at it, get some data back, job done. At no point did that data originate from, persist in (for any meaningful amount of time), or return to the external cloud. The security, availability and integrity of that data during transit and processing is by no means trivial, but compared to storing that data in the external cloud it is.
Which leads me in a roundabout way back to why apps need to change in order for internal compute clouds to reach their full potential and for external compute clouds to become really viable. Apps need to be delivered predictably and efficiently, that we may throw data at them. Whether that is achieved by virtualising them, streaming them, packaging them the traditional way, the choice is yours. But start thinking about it now, lest your clouds do nothing but rain on you.
Note that I said compute there. Indeed the cloud has many other components, but infrastructure guys like me will mainly be concerned with compute. And maybe storage. And of course what connects things to either of those 2. Hmmm. OK, maybe it's more than just compute, but for all intents and purposes I'm going to try and stay focused on compute.
So lets talk about apps. See what I did there? At the end of the day, compute is only good for one thing - running apps. But I can't see us getting to this fluffy land of external federated clouds without a fundamental change to how most applications in an enterprise environment run. Now don't get me wrong - the whole point of cloud compute from infrastructure up is that we don't have to change the apps. I get that. But in reality, they're going to have to change - they have to become portable, and any state needs to move out of the endpoint and into somewhere central. Why? Because it's gonna be a looooong time before _data_ is held in an external cloud, if ever IMHO. As Tim O'Reilly points out in his recent post Web 2.0 and Cloud Computing:
The prospect of "my" data disappearing or being unavailable is far more alarming than, for example, the disappearance of a service that merely hosts an aggregated view of data that is available elsewhere.And I think that's the key point that a lot of skeptics are missing. As an individual I hold exactly the stance that Tim describes, and all I really care about are some photos, videos, my resume and my password database. None of that stuff is required in order for me to live. What stance do you imagine companies are going to have, who's very existence depends upon data and the manipulation thereof?
Cloud compute means exactly as the name implies. COMPUTE. As in run up a compute engine (ie. an OS + App + State stack), throw some data at it, get some data back, job done. At no point did that data originate from, persist in (for any meaningful amount of time), or return to the external cloud. The security, availability and integrity of that data during transit and processing is by no means trivial, but compared to storing that data in the external cloud it is.
Which leads me in a roundabout way back to why apps need to change in order for internal compute clouds to reach their full potential and for external compute clouds to become really viable. Apps need to be delivered predictably and efficiently, that we may throw data at them. Whether that is achieved by virtualising them, streaming them, packaging them the traditional way, the choice is yours. But start thinking about it now, lest your clouds do nothing but rain on you.
Thursday 23 October 2008
VirtualCenter 2.5 Update 3 Upgrade Process - here we go again!
It seems the VirtualCenter upgrade process is not getting any better. I can't for the life of me understand how bugs like this got through with the Update 2 release, but they did and are one of the primary drivers for my company to roll out Update 3 asap (that and the security fixes). But lo, there are new upgrade problems afoot, notably this one which I have encountered 3 times now. Duncan called it out a few weeks back.
Now what really grinds my gears is that the most important fixes (for me anyway) are security related and of course the fix for the guest customisation bug. That is, binary patches - nothing at all to do with the database. In fact I can't find anything obviously database related in the release notes, and this is somewhat validated by the fact to get around this we need to append a "MINORDBUPGRADE=1" argument to VCDatabaseUpgrade.exe (the DSN, UID and PWD arguments don't appear to be necessary). So for anyone at VMware reading this, STOP TOUCHING THE VC DATABASE WHEN YOU DON'T HAVE TO. Minor DB upgrade? WTF? You're risking the VC database and ruining another persons saturday (now we need a Unix admin, a Windows admin _and_ a DBA to upgrade VC) for a MINOR UPGRADE?
Additionally, the jre binaries are not upgraded correctly as we found out when the Sun Ray environment in our lab broke after applying U3 (Sun have a KB article about this that I can't find at the moment). A clean install had no such problems however.
If VMware are going to continue with these monolithic style updates so frequently (Update 1 in April, Update 2 in July, and now Update 3 in October), they need to get their chi together. Tomcat and JRE security related bugs come out all the time, and if you work in a regulated environment then you have no choice but to patch ASAP. But having to touch the database in order to do so is the opposite of cool. Be cool VMware, be cool!
UPDATE: Here's that Sun KB article I was referring to... it actually mentions Update 2 but the same applies for Update 3
Now what really grinds my gears is that the most important fixes (for me anyway) are security related and of course the fix for the guest customisation bug. That is, binary patches - nothing at all to do with the database. In fact I can't find anything obviously database related in the release notes, and this is somewhat validated by the fact to get around this we need to append a "MINORDBUPGRADE=1" argument to VCDatabaseUpgrade.exe (the DSN, UID and PWD arguments don't appear to be necessary). So for anyone at VMware reading this, STOP TOUCHING THE VC DATABASE WHEN YOU DON'T HAVE TO. Minor DB upgrade? WTF? You're risking the VC database and ruining another persons saturday (now we need a Unix admin, a Windows admin _and_ a DBA to upgrade VC) for a MINOR UPGRADE?
Additionally, the jre binaries are not upgraded correctly as we found out when the Sun Ray environment in our lab broke after applying U3 (Sun have a KB article about this that I can't find at the moment). A clean install had no such problems however.
If VMware are going to continue with these monolithic style updates so frequently (Update 1 in April, Update 2 in July, and now Update 3 in October), they need to get their chi together. Tomcat and JRE security related bugs come out all the time, and if you work in a regulated environment then you have no choice but to patch ASAP. But having to touch the database in order to do so is the opposite of cool. Be cool VMware, be cool!
UPDATE: Here's that Sun KB article I was referring to... it actually mentions Update 2 but the same applies for Update 3
Wednesday 22 October 2008
(Red) Sun Rising...
Sun are keeping suspiciously quiet regarding their virtualisation offerings, both present and future, and you know what they say about the quiet ones. There doesn't seem to be a lot of material out there tying the various pieces of their puzzle together, and it's entirely possible this is intended to keep everyone's focus on VMware / Citrix / Microsoft. I hear a little voice... oh, sorry, you too Red Hat.
But check out what's in the pipeline with storage (starting page 13). Holy fuck - did your head just explode too? Or hows about how ALP shapes up against other remote display protocols (we've tested this first hand where I work - over high latency connections, there is _nothing_ in it between ALP and ICA). Put those pieces together with Lustre, Zones, xVM, Ops Center, and Sun Ray, all glued together with Java... and VMware should be shaking in their boots. We may well see the old kings of the datacenter back with a vengeance in the next 12-24 months.
But check out what's in the pipeline with storage (starting page 13). Holy fuck - did your head just explode too? Or hows about how ALP shapes up against other remote display protocols (we've tested this first hand where I work - over high latency connections, there is _nothing_ in it between ALP and ICA). Put those pieces together with Lustre, Zones, xVM, Ops Center, and Sun Ray, all glued together with Java... and VMware should be shaking in their boots. We may well see the old kings of the datacenter back with a vengeance in the next 12-24 months.
Tuesday 21 October 2008
System Center Virtual Machine Manager 2008 RTM's!
You read it here first... well, second besides the actual announcement.
I'll definitely be checking it out soon as it's available for end users!
Update: The eval is available for download already!
I'll definitely be checking it out soon as it's available for end users!
Update: The eval is available for download already!
Tuesday 14 October 2008
HP "Virtualization Blade" - Marketing Bullshit 1 / Virtualisation Architects 0
I'll start (as I often do with negatively titled posts) by saying that I love HP kit. No I'm not being sarcastic, back when I was a support guy I actually resigned from a place because they were going to switch their server vendor of choice away from HP. But for fucks sake, this BL495c "virtualization blade" business is _really_ getting on my nerves. Rather than explain, help me out by doing the following:
1. Google "HP Virtualization Blade"
2. Ignore Mike's #1 rank in the results (nice job Mike, how the fuck did you take top spot from HP themselves in under 1 day :D).
3. 4 or 5 results down you should see "HP ProLiant BL495c G5 Server Blade - product overview". Hit that link.
4. On the resulting page, ignore all the marketing bullshit and cast your eyes over the "Support" section of links to the right of the blade image.
5. Open the "OS support" link in a new tab. Change to that tab, and hit the "Vmware" link.
6. Go back to the main product overview page, and open the "Software & Drivers" link in another new tab.
Or if you're too lazy, have a look here and here.
Now am i going blind, or is there a complete lack of VMware support for this "virtualization blade"? Thanks for that HP. Now guys like me have to fend off a barrage of enquiries from support and management asking "why aren't you looking at the HP virtualization blade?". Ironically, Citrix XenServer 5.0 is listed as supporting the BL495c... is anyone even using that? Even if there was VMware support, good luck with using that 10GbE outside of the chassis - there isn't a 10GbE switch available for the C-class yet. And let's not ignore the other touted feature, SSD. As Mike points out in his post, disks in blades are next to useless anyway (although in my mind the future is PXE rather than embedded).
No doubt the VMware support and 10GbE switches will come in time, but until then HP should withdraw the marketing BS. It doesn't do them any favours, and no doubt posts like this will just serve as ammo for their competitors. I look forward to the day when I won't have to write such posts in the first place!
1. Google "HP Virtualization Blade"
2. Ignore Mike's #1 rank in the results (nice job Mike, how the fuck did you take top spot from HP themselves in under 1 day :D).
3. 4 or 5 results down you should see "HP ProLiant BL495c G5 Server Blade - product overview". Hit that link.
4. On the resulting page, ignore all the marketing bullshit and cast your eyes over the "Support" section of links to the right of the blade image.
5. Open the "OS support" link in a new tab. Change to that tab, and hit the "Vmware" link.
6. Go back to the main product overview page, and open the "Software & Drivers" link in another new tab.
Or if you're too lazy, have a look here and here.
Now am i going blind, or is there a complete lack of VMware support for this "virtualization blade"? Thanks for that HP. Now guys like me have to fend off a barrage of enquiries from support and management asking "why aren't you looking at the HP virtualization blade?". Ironically, Citrix XenServer 5.0 is listed as supporting the BL495c... is anyone even using that? Even if there was VMware support, good luck with using that 10GbE outside of the chassis - there isn't a 10GbE switch available for the C-class yet. And let's not ignore the other touted feature, SSD. As Mike points out in his post, disks in blades are next to useless anyway (although in my mind the future is PXE rather than embedded).
No doubt the VMware support and 10GbE switches will come in time, but until then HP should withdraw the marketing BS. It doesn't do them any favours, and no doubt posts like this will just serve as ammo for their competitors. I look forward to the day when I won't have to write such posts in the first place!
Tuesday 7 October 2008
VM Template for Citrix Provisioning Server
A rather odd bug with VirtualCenter is the inability to deploy VM's with a SCSI controller but without a disk... even creating a template from a VM that has a SCSI controller but no disk results in a template with no SCSI controller (you then have to convert it to a VM, re-add the SCSI controller, then convert back to template. Only to find the SCSI controller stripped during the deploy from template. There's 10 minutes of my life I'll never get back).
If you've been reading this blog for any length of time you'll know I'm not exactly a fan of Citrix XenServer, but Citrix Provisioning Server on the hand is _very_ cool (albeit prohibitively expensive and not without it's drawbacks... another post maybe). For the uninitiated, Provisioning Server streams a disk via the network. But obviously the streamed disk needs to be access via a disk controller (duh!). Which is why I want to create a diskless template in the first place.
Before firing up the trusty PowerShellified version of Notepad2, i did a cursory search of the VI Toolkit forum to see if someone had done this already... and surprise surprise, Cool Hand LucD had done my work for me.
So yeh, now all I need to do is deploy my scsiless and diskless template with new-vm and call the function from LucD, and all is well in the world - big ups to LucD.
/me makes W shape with fingers on one hand while simultaneously pounding fist on chest with the other
If you've been reading this blog for any length of time you'll know I'm not exactly a fan of Citrix XenServer, but Citrix Provisioning Server on the hand is _very_ cool (albeit prohibitively expensive and not without it's drawbacks... another post maybe). For the uninitiated, Provisioning Server streams a disk via the network. But obviously the streamed disk needs to be access via a disk controller (duh!). Which is why I want to create a diskless template in the first place.
Before firing up the trusty PowerShellified version of Notepad2, i did a cursory search of the VI Toolkit forum to see if someone had done this already... and surprise surprise, Cool Hand LucD had done my work for me.
So yeh, now all I need to do is deploy my scsiless and diskless template with new-vm and call the function from LucD, and all is well in the world - big ups to LucD.
/me makes W shape with fingers on one hand while simultaneously pounding fist on chest with the other
Sunday 5 October 2008
Future ESXi Version Call to Arms!
While there wasn't a lot of concrete details that came out of VMworld, one thing is for certain - VMware are working on a _lot_ of new functionality for their next major release. Of particular relevance to us at vinternals is the host profiles feature, as it provides the same functionality as Statelesx, but is done in a much more user friendly way. Which is fine - it's not like we threw in out jobs and tried to position statelesx as a commercial product, and in some ways it's a validation that our idea was a good one.
But VMware need to ensure they implement the other half of the solution, ala the client initiator. Without this, there is still an unnecessary manual task of joining a host to a cluster in the first place. You may think this isn't such a big deal, but if your hosts are PXE booted then a client initiator is an absolute requirement.
Fortunately for us, there is at least one senior guy at VMware who gets all this - Lance Berc (I get a laugh eveytime I see his 'novice' status in the VMware forums - for fucks sake, this is the guy who wrote the original esxtop). So far most attention has been on his post-build configuration scripts, but Lance put his C skills to work and released the crucial client initiator piece as well as a 'midwife' which essentially performs the same duties as statelesx. Put all this together and you have a truly automated, scalable, liquid environment - the likes of which is usually only seen in compute clusters. Except this time it's a _virtual_ environment.
VMware seem to be taking notice of the need for cluster wide configuration automation with host profiles and the distributed virtual switch, we as customers need to make sure they understand the need for the client initiator functionality as well. The 'midwife' functionality would also be nice if it was wrapped into VirtualCenter, but if it isn't then maybe Statelesx will have some longevity after all, even if it is somewhat more limited to automating the application of a host-profile that is defined elsewhere.
So here's the call to arms. We as customers have the strongest sway with regards to product features. And with a new version of the platform in development, now is the time to start hitting our account managers inboxes with requests for this functionality. Hell, just send 'em a link to this post if it makes it easier - the important thing is to push this through the account channels, not Lance (you'd just be preaching to the converted), and the time to act is now!
But VMware need to ensure they implement the other half of the solution, ala the client initiator. Without this, there is still an unnecessary manual task of joining a host to a cluster in the first place. You may think this isn't such a big deal, but if your hosts are PXE booted then a client initiator is an absolute requirement.
Fortunately for us, there is at least one senior guy at VMware who gets all this - Lance Berc (I get a laugh eveytime I see his 'novice' status in the VMware forums - for fucks sake, this is the guy who wrote the original esxtop). So far most attention has been on his post-build configuration scripts, but Lance put his C skills to work and released the crucial client initiator piece as well as a 'midwife' which essentially performs the same duties as statelesx. Put all this together and you have a truly automated, scalable, liquid environment - the likes of which is usually only seen in compute clusters. Except this time it's a _virtual_ environment.
VMware seem to be taking notice of the need for cluster wide configuration automation with host profiles and the distributed virtual switch, we as customers need to make sure they understand the need for the client initiator functionality as well. The 'midwife' functionality would also be nice if it was wrapped into VirtualCenter, but if it isn't then maybe Statelesx will have some longevity after all, even if it is somewhat more limited to automating the application of a host-profile that is defined elsewhere.
So here's the call to arms. We as customers have the strongest sway with regards to product features. And with a new version of the platform in development, now is the time to start hitting our account managers inboxes with requests for this functionality. Hell, just send 'em a link to this post if it makes it easier - the important thing is to push this through the account channels, not Lance (you'd just be preaching to the converted), and the time to act is now!
Thursday 25 September 2008
VM Reconfiguration via the VI Toolkit for Windows
Reconfiguring VM's via the API is something I've had to dabble in lately, due to some.... err.. "interesting" behaviour with deploying VM's from templates. Such as the inability to deploy a VM from a template that has a SCSI controller but no disk - useful if using LUN based snapshots, where the .vmdk already exists and you want to move said vmdk into the same directory as the VM after it's been created (and thus can't use the -Diskpath option of New-VM as the path doesn't exist yet). Or if you want to create VM's for use with Citrix Provisioning server, which don't require a local disk but do require a SCSI controller.
While this operation is uglier than I'd like it (most things that involve Get-View and specifications are uglier than I'd like them :-), I found this very good paper which explains the VI object model as applied to VM hardware reconfiguration _much_ better than the SDK documentation does.
Sure the examples are in Perl, but the theory is the same. Combine the document with a listing of all posts by Carter, LucD and halr9000 in the VI Toolkit for Windows community and there's nothing you can't do!
While this operation is uglier than I'd like it (most things that involve Get-View and specifications are uglier than I'd like them :-), I found this very good paper which explains the VI object model as applied to VM hardware reconfiguration _much_ better than the SDK documentation does.
Sure the examples are in Perl, but the theory is the same. Combine the document with a listing of all posts by Carter, LucD and halr9000 in the VI Toolkit for Windows community and there's nothing you can't do!
Wednesday 24 September 2008
Hyper-V Server - Microsoft turns platform arse-about
After a combination of holidays and letting the VMworld blog storm pass, vinternals is back!
For those who may not understand the phrase "arse-about", it means backwards. Which is exactly what Microsoft have done with the upcoming release of Hyper-V Server. The marketing around this product seems to have been a bit lost, so let's recap exactly what this product is (and is not)
- Hyper-V Server is NOT running Windows Server Core 2008 in the parent partition
- Hyper-V Server is aimed at small / dev environments, not enterprises
- Hyper-V Server is running little more than the Windows Server driver model and the virtualisation stack in the parent partition
- Hyper-V Server has the same underlying hypervisor and virtual bus architecture as the Hyper-V found in full-blown Windows Server 2008
So why have Microsoft got the platform ass-about (US English :-)? Because their own best practice recommends keeping the parent partition as lean as possible from an application perspective. So why the hell aren't they keeping the parent partition as lean as possible from an OS perspective? Windows Driver model + virtualisation stack - that's what I want in an ENTERPRISE Microsoft virtualisation platform! I don't want to be running something in the parent partition that is subject to patches like this one! But instead Hyper-V Server is being positioned as the red haired step child of the Microsoft virtualisation offerings.
I'll still take a look at Hyper-V Server when it comes out... there are some fundamental infrastructure design differences that may not be so obvious to those of us who have been designing VMware infrastructures for a while, that may still be applicable to Hyper-V Server... sounds like a good topic for SAAAP :-)
For those who may not understand the phrase "arse-about", it means backwards. Which is exactly what Microsoft have done with the upcoming release of Hyper-V Server. The marketing around this product seems to have been a bit lost, so let's recap exactly what this product is (and is not)
- Hyper-V Server is NOT running Windows Server Core 2008 in the parent partition
- Hyper-V Server is aimed at small / dev environments, not enterprises
- Hyper-V Server is running little more than the Windows Server driver model and the virtualisation stack in the parent partition
- Hyper-V Server has the same underlying hypervisor and virtual bus architecture as the Hyper-V found in full-blown Windows Server 2008
So why have Microsoft got the platform ass-about (US English :-)? Because their own best practice recommends keeping the parent partition as lean as possible from an application perspective. So why the hell aren't they keeping the parent partition as lean as possible from an OS perspective? Windows Driver model + virtualisation stack - that's what I want in an ENTERPRISE Microsoft virtualisation platform! I don't want to be running something in the parent partition that is subject to patches like this one! But instead Hyper-V Server is being positioned as the red haired step child of the Microsoft virtualisation offerings.
I'll still take a look at Hyper-V Server when it comes out... there are some fundamental infrastructure design differences that may not be so obvious to those of us who have been designing VMware infrastructures for a while, that may still be applicable to Hyper-V Server... sounds like a good topic for SAAAP :-)
Thursday 4 September 2008
Qumranet Acquisition - what does it mean for SPICE?
Sure I'm the 100th blogger to chime in on the Red Hat acquisition of Qumranet, however one thing that seems to be escaping the press is the completely proprietary nature of the SPICE protocol, which is really what made Qumranet stand out from the other KVM based solutions on the market (that and the fact that they were the sole commercial sponsor of the KVM project, the same that Parallels is the sponsor of OpenVZ).
I met Moshe Bar earlier this year, and asked him if SPICE was intrinsic to KVM, and if not why not license it to other vendors in the VDI space. His reply was that they could indeed re-engineer and license SPICE to any vendor, however doing so would pretty much kill the rest of their offering. If Red Hat open source SPICE, there could be some interesting developments in the remote display protocol / broker space indeed. I don't know how many of you have seen SPICE running live, but it's pretty darn impressive!
I met Moshe Bar earlier this year, and asked him if SPICE was intrinsic to KVM, and if not why not license it to other vendors in the VDI space. His reply was that they could indeed re-engineer and license SPICE to any vendor, however doing so would pretty much kill the rest of their offering. If Red Hat open source SPICE, there could be some interesting developments in the remote display protocol / broker space indeed. I don't know how many of you have seen SPICE running live, but it's pretty darn impressive!
Sunday 31 August 2008
PowerAlarm Manager Script
Check out Shyam's entry in the (now closed) VI Toolkit for Windows Scripting Contest, PowerAlarm Manager. It allows you to create alarms on any item in the VC inventory based on any perf metric. This is way cool - I've never quite understood why this functionality is not natively available. The Ready Time metric for example, is very useful as I'm sure anyone reading this blog knows. But we've never been able to create alarms based on it until now, thanks to Shyam!
So here's hoping he gets a placing in the top 3, although with some very good entries in there it will be tough. We'll post back any results as they come to hand, but in the meantime you should check it out and please report any bugs back to us!
So here's hoping he gets a placing in the top 3, although with some very good entries in there it will be tough. We'll post back any results as they come to hand, but in the meantime you should check it out and please report any bugs back to us!
Thursday 14 August 2008
Statelesx 1.1.0 Released!
Yes yes, hard to believe but we have had a great response from the initial release from people all over the globe, including some improvements that we thought should go in straight away!
In this release, we have added:
- hosts that contact the appliance via the python script now are placed into an "unregistered hosts" section, making it very easy to add them to clusters (ie no more typing in hostname and UUID)
- hosts that are defined in clusters can be configured via a single button click in the web UI, so no python script is needed on the host. Yes, that means you can now configure ESXi boxes. You still need VirtualCenter though, and it's obviously not a completely hands off process since you still need a single button click to initiate the configuration, but we're working on that.
- web interface now located at http://[IP.Address.of.Appliance]/
Credentials are the same as the initial release (root / root for console, statelesx / statelesx for web interface). The new md5 sum is:
98aaea31137048338a547a56dd2a65c2 statelesx-1.1.0-ovf.zip
The python script also has a minor update, now 2 parameters are sent across:
#!/usr/bin/python
import socket
import re
import sys
#Open esx.conf, read only
esxconf = open("/etc/vmware/esx.conf", "r")
#Define regular expressions
getName = re.compile("/adv/Misc/HostName.=.(.*)")
getUUID = re.compile ("/system/uuid.=.(.*)")
#Search esx.conf for matches
for line in esxconf.readlines():
hostname = getName.findall(line)
for name in hostname:
name = name.strip('"')
UUID = getUUID.findall(line)
for uuid in UUID:
uuid = uuid.strip('"')
#Close esx.conf
esxconf.close()
#Define statelesx server address, port and msg
host = sys.argv[1]
port = 1974
msg = name + ":" + uuid
#Open socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
#Connect socket
s.connect((host,port))
#Send msg
print "Sending " + msg
s.send(msg)
# Close socket
s.close()
We hope you enjoy this release, feel free to mail us with any feature requests / bug reports or leave them in comments section of this post!
In this release, we have added:
- hosts that contact the appliance via the python script now are placed into an "unregistered hosts" section, making it very easy to add them to clusters (ie no more typing in hostname and UUID)
- hosts that are defined in clusters can be configured via a single button click in the web UI, so no python script is needed on the host. Yes, that means you can now configure ESXi boxes. You still need VirtualCenter though, and it's obviously not a completely hands off process since you still need a single button click to initiate the configuration, but we're working on that.
- web interface now located at http://[IP.Address.of.Appliance]/
Credentials are the same as the initial release (root / root for console, statelesx / statelesx for web interface). The new md5 sum is:
98aaea31137048338a547a56dd2a65c2 statelesx-1.1.0-ovf.zip
The python script also has a minor update, now 2 parameters are sent across:
#!/usr/bin/python
import socket
import re
import sys
#Open esx.conf, read only
esxconf = open("/etc/vmware/esx.conf", "r")
#Define regular expressions
getName = re.compile("/adv/Misc/HostName.=.(.*)")
getUUID = re.compile ("/system/uuid.=.(.*)")
#Search esx.conf for matches
for line in esxconf.readlines():
hostname = getName.findall(line)
for name in hostname:
name = name.strip('"')
UUID = getUUID.findall(line)
for uuid in UUID:
uuid = uuid.strip('"')
#Close esx.conf
esxconf.close()
#Define statelesx server address, port and msg
host = sys.argv[1]
port = 1974
msg = name + ":" + uuid
#Open socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
#Connect socket
s.connect((host,port))
#Send msg
print "Sending " + msg
s.send(msg)
# Close socket
s.close()
We hope you enjoy this release, feel free to mail us with any feature requests / bug reports or leave them in comments section of this post!
Sunday 10 August 2008
Statelesx Initiator Script
In all our anxiousness to get the statelesx 1.0.0 appliance out, we totally forgot to post up the client initiator script! So here it is:
#!/usr/bin/python
import socket
import sys
import re
#Open esx.conf, read only
esxconf = open("/etc/vmware/esx.conf", "r")
#Define regular expressions
getUUID = re.compile ("/system/uuid.=.(.*)")
#Search esx.conf for matches
for line in esxconf.readlines():
UUID = getUUID.findall(line)
for uuid in UUID:
uuid = uuid.strip('"')
#Close esx.conf
esxconf.close()
#Define statelesx server address (from argument), port and msg
host = sys.argv[1]
port = 1974
msg = uuid
#Open socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
#Connect socket
s.connect((host,port))
#Send msg
print "Sending " + msg
s.send(msg)
# Close socket
s.close()
Just drop that onto your fat ESX 3.5 box and run it as one of the last startup scripts.
#!/usr/bin/python
import socket
import sys
import re
#Open esx.conf, read only
esxconf = open("/etc/vmware/esx.conf", "r")
#Define regular expressions
getUUID = re.compile ("/system/uuid.=.(.*)")
#Search esx.conf for matches
for line in esxconf.readlines():
UUID = getUUID.findall(line)
for uuid in UUID:
uuid = uuid.strip('"')
#Close esx.conf
esxconf.close()
#Define statelesx server address (from argument), port and msg
host = sys.argv[1]
port = 1974
msg = uuid
#Open socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
#Connect socket
s.connect((host,port))
#Send msg
print "Sending " + msg
s.send(msg)
# Close socket
s.close()
Just drop that onto your fat ESX 3.5 box and run it as one of the last startup scripts.
Friday 8 August 2008
VirtualCenter 2.5 Update 2 Database Changes
After my previous postings on the VirtualCenter upgrade process, I had some correspondence with VMware devs that was proxied by John Troyer from the VMTN Blog. During the course of that correspondence, I lamented the generic names given to the stats rollup SQL agent jobs. SQL agent jobs are created per-instance and thus having generic names would be problematic in a shared SQL environment - effectively, you'd need a SQL instance per VC database, instead of a single SQL instance with many VC databases. Not exactly an optimal use of resources on the SQL box.
But surprise surprise - today I installed VC 2.5 Update 2, and guess what I saw
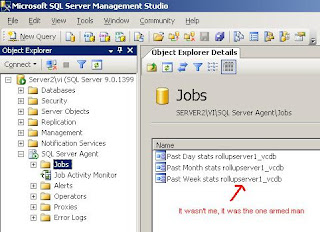
As you've probably guessed, 'server1_vcdb' is the name of my VC database. Sure, they probably meant to put a space in between 'rollup' and [databasename], but don't I feel just a little bit special ^_^. Thanks guys.
But surprise surprise - today I installed VC 2.5 Update 2, and guess what I saw

As you've probably guessed, 'server1_vcdb' is the name of my VC database. Sure, they probably meant to put a space in between 'rollup' and [databasename], but don't I feel just a little bit special ^_^. Thanks guys.
Thursday 7 August 2008
Download statelesx 1.0.0 now!
A big thanks to all those who responded with offers of help for the hosting, the first of who was Dan Milisic over at DesktopECHO who of course has an appliance of his own! Jeff O'Connor from VMware Australia was hot on his heels with some bandwidth too, thanks for that mate :-)
Hit the download links over on the right, the details you need to know for the appliance are:
md5sum: 4e3c8b29d2069ff52afe97b910451595 statelesx-1.0.0-ovf.zip
IP Address: DHCP
Root password: root
Statelesx Web Interface: http://[IP address of appliance]/statelesxWI
statelesxWI username: statelesx
statelesxWI password: statelesx
Please send all bug reports / feature requests to vinternals@gmail.com, and for anyone in London lookout for us at the next VMware User Group meeting on August 14th!
Hit the download links over on the right, the details you need to know for the appliance are:
md5sum: 4e3c8b29d2069ff52afe97b910451595 statelesx-1.0.0-ovf.zip
IP Address: DHCP
Root password: root
Statelesx Web Interface: http://[IP address of appliance]/statelesxWI
statelesxWI username: statelesx
statelesxWI password: statelesx
Please send all bug reports / feature requests to vinternals@gmail.com, and for anyone in London lookout for us at the next VMware User Group meeting on August 14th!
Friday 1 August 2008
Announcing Statelesx 1.0.0!
Today marks a great day for us over here... the release of our first application, Statelesx (pronounced "stateless" - think of the X in xsigo or xenophobia).
As anyone who has been reading this blog since it's inception knows, statelessness of the endpoint is something I strongly believe in. And with statelesx, you can achieve this. The architecture of the app is something like this:
1) A python script on your fat ESX boxes that runs on startup
2) A Java app that listens for requests and acts via the VirtualCenter SDK
3) A minimal web interface for managing XML cluster configuration files
In a nutshell, you create a cluster configuration file that contains cluster options (DRS,DPM,HA) and network info (vSwitches, portgroups, vmkernel interfaces) and then associate hosts to the cluster config file by their FQDN and UUID. The python script on the ESX host sends the UUID to the statelesx listener, which searches the cluster config files for a match on the UUID. If it finds one, it goes to work. If it doesn't, nothing happens.
It goes without saying, this has a lot of implications. It cuts the shit out of deployment time. It saves admins the rather boring and repetitive task of configuring esx hosts individually when new clusters hit the datacenter floor. You dont have to backup your esx configs anymore - it would be quicker to rebuild from scratch and let statelesx configure things for you. And finally, it ensures you have a 100% consistent cluster wide networking configuration.
Statelesx will be available as a virtual appliance. It runs on Ubuntu 8.04 JeOS with the Sun Java 6 package and Tomcat 6. All up the appliance is only a few hundred megs of disk, and half a gig of RAM although no doubt it could run with less if you needed it to. VI 3.5 is required, although if we get enough requests we may backport to VI 3.0.
We've put together some videos to show you it in action - be sure to watch them in full screen mode as they're recorded at 1024 x 768. The first one gives an overview and basic configuration demo. The second one goes into much more detail around the XML config files and shows an advanced configuration being applied to some hosts.
Plea for hosting!
The problem we have now, is that we dont have anywhere to host the appliance itself. Even though it zips down to under 200MB, we couldn't find any free providers that would allow the bandwidth we're hopefully going to receive when everyone realises how useful the app is :-D. So if anyone reading can help out in this regard, please contact us on vinternals at gmail dot com.
Hopefully we'll be adding a download link soon!
As anyone who has been reading this blog since it's inception knows, statelessness of the endpoint is something I strongly believe in. And with statelesx, you can achieve this. The architecture of the app is something like this:
1) A python script on your fat ESX boxes that runs on startup
2) A Java app that listens for requests and acts via the VirtualCenter SDK
3) A minimal web interface for managing XML cluster configuration files
In a nutshell, you create a cluster configuration file that contains cluster options (DRS,DPM,HA) and network info (vSwitches, portgroups, vmkernel interfaces) and then associate hosts to the cluster config file by their FQDN and UUID. The python script on the ESX host sends the UUID to the statelesx listener, which searches the cluster config files for a match on the UUID. If it finds one, it goes to work. If it doesn't, nothing happens.
It goes without saying, this has a lot of implications. It cuts the shit out of deployment time. It saves admins the rather boring and repetitive task of configuring esx hosts individually when new clusters hit the datacenter floor. You dont have to backup your esx configs anymore - it would be quicker to rebuild from scratch and let statelesx configure things for you. And finally, it ensures you have a 100% consistent cluster wide networking configuration.
Statelesx will be available as a virtual appliance. It runs on Ubuntu 8.04 JeOS with the Sun Java 6 package and Tomcat 6. All up the appliance is only a few hundred megs of disk, and half a gig of RAM although no doubt it could run with less if you needed it to. VI 3.5 is required, although if we get enough requests we may backport to VI 3.0.
We've put together some videos to show you it in action - be sure to watch them in full screen mode as they're recorded at 1024 x 768. The first one gives an overview and basic configuration demo. The second one goes into much more detail around the XML config files and shows an advanced configuration being applied to some hosts.
Plea for hosting!
The problem we have now, is that we dont have anywhere to host the appliance itself. Even though it zips down to under 200MB, we couldn't find any free providers that would allow the bandwidth we're hopefully going to receive when everyone realises how useful the app is :-D. So if anyone reading can help out in this regard, please contact us on vinternals at gmail dot com.
Hopefully we'll be adding a download link soon!
Sunday 27 July 2008
Vinternals Doubles in Size!
Over the past few months I've been working away in the secret Vinternals coding labs on a virtual appliance with an esteemed colleague and virtualisation extraordinaire, Shyam Madhavan. What we've managed to put together is something we reckon is pretty amazing, and we hope to have something ready for you all in the next few days.
And here's the best part - it will be completely free.
After putting in such a monumental effort, it is only fair that he be rewarded with the massive fame and money that one can expect as a 50% partner in vinternals (needless to say, Shyam won't be quitting his day job). Keep your eyes peeled for some postings over the coming months / years, and be sure to check the site later in the week for more information on the appliance!
And here's the best part - it will be completely free.
After putting in such a monumental effort, it is only fair that he be rewarded with the massive fame and money that one can expect as a 50% partner in vinternals (needless to say, Shyam won't be quitting his day job). Keep your eyes peeled for some postings over the coming months / years, and be sure to check the site later in the week for more information on the appliance!
Wednesday 23 July 2008
PowerShell - Create X Number of VM's per Datastore
We all love the 'shell, and the VI Toolkit for Windows even more. When i finish up with some other stuff, I'll surely be pointing my C# skills at some cmdlets for that.
Anyway, there are a load of "create VM" scripts out there, I thought I'd show you one with a useful twist - create a certain number of sequentially numbered VM's per datastore. For those new to the way of the 'Shell, # is a comment (unlike batch or vbscript)
There you have it. The only caveat is that the datastores don't get returned by name so if you have sequentially numbered datatstores and want the VM numbers to match (ie VM1 - VM10 on 'datastore 1', VM11 - VM20 on 'datastore 2'), you'll need to pump the datastores into an array and -sort it first or something. I'll leave the intrepid reader to handle that if required :-)
Anyway, there are a load of "create VM" scripts out there, I thought I'd show you one with a useful twist - create a certain number of sequentially numbered VM's per datastore. For those new to the way of the 'Shell, # is a comment (unlike batch or vbscript)
$esx = Get-VMHost -Name esx.host.name
$template = Get-Template -name TEMPLATE-NAME
$x = 1
#loop through all datastores on host
foreach ($d in Get-Datastore -vmhost $esx)
{
#check that it's not a local datastore
if (!($d.name -match ":"))
{
#loop to create 10 VM's per datastore
for ($i=$x; $i -lt ($x + 10); $i++)
{
#append a number to VM name
$vmname = "VM" + "$i";
#create the VM from template
New-VM -Name $vmname -Template $template -Datastore $d -Host $esx
}
#set $x to the next number in sequence for the next datastore
$x = $i
}
}
There you have it. The only caveat is that the datastores don't get returned by name so if you have sequentially numbered datatstores and want the VM numbers to match (ie VM1 - VM10 on 'datastore 1', VM11 - VM20 on 'datastore 2'), you'll need to pump the datastores into an array and -sort it first or something. I'll leave the intrepid reader to handle that if required :-)
ESXi Free by End of July!
Yes I've been quiet of late, but for a very good reason... which I'll divulge maybe on the weekend ;-)
But todays news (Alessandro - you are a machine aren't you? When do you sleep!) was just too big to let go by - ESXi is finally free. Well... finally officially free - technically it's been free for ages, all you had to was download a patch for it, as ESXi patches are essentially entire new images (although of course it would've run in eval mode for 60 days... by which time another patch would have come out ;-)
This is a great way for VMware to hit back after the raft of troubles lately. All the arguments from Microsoft, Xen, etc have always been about price, and they no longer have a leg to stand on.
This actually makes Hyper-V more expensive than ESXi, as you still have to pay for the Windows OS in the parent partition. And pay for no less than Enterprise Edition if you want to cluster Hyper-V. Lets not forget the storage add-ons if you want a clustered file system.
This puts the ball squarely back in the competition's court, and might as well be the final nail in the coffin for Citrix XenServer as it is now the only major commercial hypervisor on the market you have to pay for.
But todays news (Alessandro - you are a machine aren't you? When do you sleep!) was just too big to let go by - ESXi is finally free. Well... finally officially free - technically it's been free for ages, all you had to was download a patch for it, as ESXi patches are essentially entire new images (although of course it would've run in eval mode for 60 days... by which time another patch would have come out ;-)
This is a great way for VMware to hit back after the raft of troubles lately. All the arguments from Microsoft, Xen, etc have always been about price, and they no longer have a leg to stand on.
This actually makes Hyper-V more expensive than ESXi, as you still have to pay for the Windows OS in the parent partition. And pay for no less than Enterprise Edition if you want to cluster Hyper-V. Lets not forget the storage add-ons if you want a clustered file system.
This puts the ball squarely back in the competition's court, and might as well be the final nail in the coffin for Citrix XenServer as it is now the only major commercial hypervisor on the market you have to pay for.
Monday 30 June 2008
Brian Madden predicts end of Citrix XenServer... I completely agree!
Brian Madden made an interesting post today, predicting the end for Citrix XenServer as we know it.
I'm not so sure about the disappearance of Xen from the landscape altogether, but on the disappearance of Citrix XenServer I agree 100%.
I think there's one more aspect worth mentioning that he doesn't touch on... the fact that 99.999% of Citrix admins are Windows admins. Windows admins are about as likely to deploy Linux based solutions as Linux admins are to deploy Windows solutions. Given that the vast majority if x86 virtualisation going on right now involves Windows guests, and there is so much feature parity between XenServer and Hyper-V that it ain't funny, I know which one I'd go with if ESX wasn't an option.
As Brian points out in his post, the value for Citrix in any market has little to do with what's underneath - it's about what they can offer on top. In the virtualisation game, the money for Citrix is in the XenDesktop broker (although currently it's a bit more like a broken than a broker IMHO) - not a Linux based hypervisor.
Citrix knows where their bread is buttered - their position in the market today is based on embracing and extending Microsoft technologies (XenApp for Unix anyone? No, didn't think so). I'm sure it won't take long for Citrix execs to see a gap in the deployment of the XenDesktop broker on ESX / Hyper-V versus the deployment of it on XenServer and wonder why the hell they are even bothering.
[UPDATE] Brian has posted a clarification - turns out I've misinterpreted his original post. Which means I'm going it alone with the prediction of Citrix XenServer's demise (_not_ the demise of the Xen hypervisor), and can claim full credit when it happens :-D
I'm not so sure about the disappearance of Xen from the landscape altogether, but on the disappearance of Citrix XenServer I agree 100%.
I think there's one more aspect worth mentioning that he doesn't touch on... the fact that 99.999% of Citrix admins are Windows admins. Windows admins are about as likely to deploy Linux based solutions as Linux admins are to deploy Windows solutions. Given that the vast majority if x86 virtualisation going on right now involves Windows guests, and there is so much feature parity between XenServer and Hyper-V that it ain't funny, I know which one I'd go with if ESX wasn't an option.
As Brian points out in his post, the value for Citrix in any market has little to do with what's underneath - it's about what they can offer on top. In the virtualisation game, the money for Citrix is in the XenDesktop broker (although currently it's a bit more like a broken than a broker IMHO) - not a Linux based hypervisor.
Citrix knows where their bread is buttered - their position in the market today is based on embracing and extending Microsoft technologies (XenApp for Unix anyone? No, didn't think so). I'm sure it won't take long for Citrix execs to see a gap in the deployment of the XenDesktop broker on ESX / Hyper-V versus the deployment of it on XenServer and wonder why the hell they are even bothering.
[UPDATE] Brian has posted a clarification - turns out I've misinterpreted his original post. Which means I'm going it alone with the prediction of Citrix XenServer's demise (_not_ the demise of the Xen hypervisor), and can claim full credit when it happens :-D
Manually Remove Datastores from VirtualCenter 2.0.x Database
Removing invalid datastores from the VirtualCenter database (in 2.0.x at least) is a bit of a pain... y'know, the ones that don't actually surface in the UI but you know are there because you get a "duplicate name" style error when adding a new datastore.
Manually editing the VirtualCenter database should never be taken lightly, and if there's a stored procedure or something that actually does this then someone please let me know. Otherwise, do the following:
1) Stop the VirtualCenter service and BACKUP THE VIRTUALCENTER DATABASE
2) Fire up whatever database management tool you like and connect to the VirtualCenter database.
3) Fire off the following query:
4) Find the offending datastore in the returned results, and make a note of the ID number (the first column)
5) Fire off another query:
6) Delete all rows returned from this query - all the values should be NULL (except the DS_ID column of course)
7) Go back to the VPX_DATASTORE table and delete the row with the non-existent datastore in it
In the case where you have a number of hosts that show as "inaccessible" as a result, you could put together a few more queries to handle that too... or even better do it in PowerShell! Hmmm, will have a look at that a bit later.
Manually editing the VirtualCenter database should never be taken lightly, and if there's a stored procedure or something that actually does this then someone please let me know. Otherwise, do the following:
1) Stop the VirtualCenter service and BACKUP THE VIRTUALCENTER DATABASE
2) Fire up whatever database management tool you like and connect to the VirtualCenter database.
3) Fire off the following query:
select * from VPX_DATASTORE
4) Find the offending datastore in the returned results, and make a note of the ID number (the first column)
5) Fire off another query:
select * from VPX_DS_ASSIGNMENT where DS_ID = id of datatstore to delete from previous query
6) Delete all rows returned from this query - all the values should be NULL (except the DS_ID column of course)
7) Go back to the VPX_DATASTORE table and delete the row with the non-existent datastore in it
In the case where you have a number of hosts that show as "inaccessible" as a result, you could put together a few more queries to handle that too... or even better do it in PowerShell! Hmmm, will have a look at that a bit later.
Sunday 29 June 2008
Hyper-V on Every Box in the Enterprise
Yes, it's more Sunday evening than afternoon but I'm gonna squeeze this one in under the guise of another installment of Sunday Afternoon Architecture And Philosophy.
With the release of Hyper-V 1.0, I got to thinking... why wouldn't you put it on every x64 physical box in the enterprise? Theoretically, the parent partition should incur no virtualisation overhead - it has physical hardware access and doesn't need to worry about managing VM's if it's running on it's own. It doesn't cost anything more for software assurance customers, and let's face it - if you're running a physical box today (and according to IDC and the like, 80-90% of servers are still physical) then almost all the reasons for choosing ESX over Hyper-V simply don't apply as you don't get any of those features with physical boxes anyway. So if that phsyical box is running at 5% resource utilisation and the owner has a need for another environment (be it for dev, UAT, tiering an app, whatever), if we have Hyper-V installed already then we have the potential to exceed expectation by quickly provisioning a box for them that doesn't require the (usually) lengthy process of ordering and racking. If we think of virtualisation purely in terms of maximising hardware utilisation, then as far as I'm concerned there's no argument to be had - I'd rather have one less physical box by running it on Hyper-V than not having Hyper-V at all.
Of course we all know there are so many other benefits to be had by virtualising on VI3, but as I said if only 10% of boxes are virtual currently then we're missing something. Maybe your business is still uncomfortable with virtualisation. Maybe your chargeback model is so close to the cost of physical boxes that your business doesn't care to virtualise (naively ignoring the cost of rack space, power, cooling and having to build a new datacenter when you run out of those). I'm sure there are a myriad of reasons, and even more certain that none of them are technical. But if we can leverage Hyper-V by putting it on every box and giving our business customers a taste of virtualisation, then maybe we can effect a change in attitude. And maybe next time they go to buy that physical box, they'll ask around as to how that virtual box has been running and reconsider. We've tried the 'boil the ocean' approach with virtualisation over the past few years, and it clearly hasn't worked if only 10% of servers are virtual. It's time for baby steps.
So to wrap it up, let me be absolutely clear - I'm not suggesting we start migrating our virtual infrastructures to Hyper-V now or in the forseeable future. What I am suggesting is that we don't write off Hyper-V by comparing it with VI3 and closing the door on it immediately. A slightly unconventional use case it may be, but it could be the most valuable tool we have had so far in assisting with the virtualisation of that other 80% of the enterprise. And I certainly hope that VMware will imminently release an update to Converter to provide full support for V2V from Hyper-V ;-)
With the release of Hyper-V 1.0, I got to thinking... why wouldn't you put it on every x64 physical box in the enterprise? Theoretically, the parent partition should incur no virtualisation overhead - it has physical hardware access and doesn't need to worry about managing VM's if it's running on it's own. It doesn't cost anything more for software assurance customers, and let's face it - if you're running a physical box today (and according to IDC and the like, 80-90% of servers are still physical) then almost all the reasons for choosing ESX over Hyper-V simply don't apply as you don't get any of those features with physical boxes anyway. So if that phsyical box is running at 5% resource utilisation and the owner has a need for another environment (be it for dev, UAT, tiering an app, whatever), if we have Hyper-V installed already then we have the potential to exceed expectation by quickly provisioning a box for them that doesn't require the (usually) lengthy process of ordering and racking. If we think of virtualisation purely in terms of maximising hardware utilisation, then as far as I'm concerned there's no argument to be had - I'd rather have one less physical box by running it on Hyper-V than not having Hyper-V at all.
Of course we all know there are so many other benefits to be had by virtualising on VI3, but as I said if only 10% of boxes are virtual currently then we're missing something. Maybe your business is still uncomfortable with virtualisation. Maybe your chargeback model is so close to the cost of physical boxes that your business doesn't care to virtualise (naively ignoring the cost of rack space, power, cooling and having to build a new datacenter when you run out of those). I'm sure there are a myriad of reasons, and even more certain that none of them are technical. But if we can leverage Hyper-V by putting it on every box and giving our business customers a taste of virtualisation, then maybe we can effect a change in attitude. And maybe next time they go to buy that physical box, they'll ask around as to how that virtual box has been running and reconsider. We've tried the 'boil the ocean' approach with virtualisation over the past few years, and it clearly hasn't worked if only 10% of servers are virtual. It's time for baby steps.
So to wrap it up, let me be absolutely clear - I'm not suggesting we start migrating our virtual infrastructures to Hyper-V now or in the forseeable future. What I am suggesting is that we don't write off Hyper-V by comparing it with VI3 and closing the door on it immediately. A slightly unconventional use case it may be, but it could be the most valuable tool we have had so far in assisting with the virtualisation of that other 80% of the enterprise. And I certainly hope that VMware will imminently release an update to Converter to provide full support for V2V from Hyper-V ;-)
Thursday 26 June 2008
Hyper-V 1.0 released - let the Hyper-bole begin!
Well it's all over the web, and I generally try not to report on stuff that everyone else does but I'm making an exception this time... more so I can remember the date than anything else ;-)
Download here now!
Download here now!
Wednesday 25 June 2008
Citrix Connection Broker Sends Support 6 Years Backwards?
To be fair to Citrix, I'll start by saying that this appears to be a Microsoft bug. But that doesn't change the magnitude of what can only be described as a monumental clusterfuck - it doesn't matter who's at fault, the problem exists today and will exist in the forseeable future unless we as Citrix and Microsoft customers put the hard word on both companies, now. And that is the absolute intention of this post - not to rubbish Citrix or Microsoft, but to get a strong message out that this needs to be fixed yesterday.
As far as I'm concerned, if you're a big Citrix shop then there is no other choice for a broker - the integration with XenApp's Web Interface, the soon-to-be single client, and the power of ICA on the desktop... it's pretty much a no brainer if you have a lot of this technology in your estate already. And even more of a no brainer if your VDI users are on the end of a >100ms latency.
Except that it could cripple your support organisation.
There is a bug that manifests when an RDP connection is made to Session0 (ie, the console session) which effectively renders the PortICA stack inoperable after that connection is terminated. That is to say, when someone uses Remote Assistance to get support, they will not be able to reconnect to that desktop via ICA after the session is terminated without a reboot of the box. So what do Citrix recommend you do to avoid this problem? Disable RDP of course!
[EDIT] I didn't explain it very well above... connecting via RDP to the console of a machine running XenDesktop 2.0 results in (a) the ICA session terminating immediately and (b) the box rebooting automatically after the RDP session is terminated.
But since XenDesktop actually remotes the physical display of the machine, the console is completely black when viewed via the VI client or VI Web Access so you can't use that for remote support. And you can't shadow PortICA sessions like you can with server-side ICA sessions either. But you don't need remote assistance... do you?
Almost every large enterprise I have worked has a remote first line of support. And almost as common is the outsourcing of the 2nd line desktop support, ie the ppl who perpetuate sneakernet. And most of those large enterprises stopped paying for 3rd party remote support solutions long ago (a substantial saving for places with over 50K desktops). Remote Assistance is a critical tool, both for speedy case resolution and for keeping support costs down (those physcial bodies are way more expensive than the ones on the end of the phone), both of which make for happy users and a happy business. Well, happier users and business at least. And it all comes free with Windows XP.
Hence the Citrix recommended workaround for this problem of disabling RDP if you install XenDesktop is utterly ridiculous and untenable IMHO. After spending years worth of time and who knows how much money on training your users to use Remote Assistance, you now have to switch it off and find some other way to get the functionality? Might that be buying GoToAssist by any chance? If Citrix have any hope of a quick resolution to this problem, they had better start bundling that with the XenDesktop standard edition license. Or get the session shadowing capabilities that have been available in Presentation Server for many years into XenDesktop ASAP.
So getting back to where this post started, XenDesktop 2.0 in its current state may send you right back to the pre-XP days, where a physical body had to go to a users desk in order to observe, understand and resolve a problem. Or you had to pay through the nose for a 3rd party remote support tool.
I don't know which is sadder - the fact that a phsyical person may need to go to a physical desk to fix a problem on a machine that isn't physically there, or the irony that a company who prides themselves of providing remote access solutions could put us in this position.
As far as I'm concerned, if you're a big Citrix shop then there is no other choice for a broker - the integration with XenApp's Web Interface, the soon-to-be single client, and the power of ICA on the desktop... it's pretty much a no brainer if you have a lot of this technology in your estate already. And even more of a no brainer if your VDI users are on the end of a >100ms latency.
Except that it could cripple your support organisation.
There is a bug that manifests when an RDP connection is made to Session0 (ie, the console session) which effectively renders the PortICA stack inoperable after that connection is terminated. That is to say, when someone uses Remote Assistance to get support, they will not be able to reconnect to that desktop via ICA after the session is terminated without a reboot of the box. So what do Citrix recommend you do to avoid this problem? Disable RDP of course!
[EDIT] I didn't explain it very well above... connecting via RDP to the console of a machine running XenDesktop 2.0 results in (a) the ICA session terminating immediately and (b) the box rebooting automatically after the RDP session is terminated.
But since XenDesktop actually remotes the physical display of the machine, the console is completely black when viewed via the VI client or VI Web Access so you can't use that for remote support. And you can't shadow PortICA sessions like you can with server-side ICA sessions either. But you don't need remote assistance... do you?
Almost every large enterprise I have worked has a remote first line of support. And almost as common is the outsourcing of the 2nd line desktop support, ie the ppl who perpetuate sneakernet. And most of those large enterprises stopped paying for 3rd party remote support solutions long ago (a substantial saving for places with over 50K desktops). Remote Assistance is a critical tool, both for speedy case resolution and for keeping support costs down (those physcial bodies are way more expensive than the ones on the end of the phone), both of which make for happy users and a happy business. Well, happier users and business at least. And it all comes free with Windows XP.
Hence the Citrix recommended workaround for this problem of disabling RDP if you install XenDesktop is utterly ridiculous and untenable IMHO. After spending years worth of time and who knows how much money on training your users to use Remote Assistance, you now have to switch it off and find some other way to get the functionality? Might that be buying GoToAssist by any chance? If Citrix have any hope of a quick resolution to this problem, they had better start bundling that with the XenDesktop standard edition license. Or get the session shadowing capabilities that have been available in Presentation Server for many years into XenDesktop ASAP.
So getting back to where this post started, XenDesktop 2.0 in its current state may send you right back to the pre-XP days, where a physical body had to go to a users desk in order to observe, understand and resolve a problem. Or you had to pay through the nose for a 3rd party remote support tool.
I don't know which is sadder - the fact that a phsyical person may need to go to a physical desk to fix a problem on a machine that isn't physically there, or the irony that a company who prides themselves of providing remote access solutions could put us in this position.
Tuesday 17 June 2008
New(ish) blog by Chad Sakac - bookmark / add feed NOW!
Quite a few things of note happened while I was away, but one thing that didn't seem to be widely reported was the launch of Chad Sakac's blog. Chad has bolted from the gate with some great posts which I won't bother linking because you should just hit his blog and read everything.
I also owe him a public apology - a while back I posted about storage stuff and made a flippant remark about "some marketing guy" in an EMC video on You Tube, which was Chad. We've had a fair bit of correspondence since then, and he is obviously about as far from a marketer as you can get. Sorry about that mate, and welcome to the blogosphere :-)
I also owe him a public apology - a while back I posted about storage stuff and made a flippant remark about "some marketing guy" in an EMC video on You Tube, which was Chad. We've had a fair bit of correspondence since then, and he is obviously about as far from a marketer as you can get. Sorry about that mate, and welcome to the blogosphere :-)

Tuesday 20 May 2008
What a time to be going offline...
Jeez I dunno... Citrix XenDesktop 2.0, the final Hyper-V RC, the System Center Virtual Machine Manager 2008 beta, ESX guest support back in the latest Workstation 6.5 beta build... and here's me going on holiday!
Still, given the choice of checking these products out in detail or roaming around Italy, I think I'll stick with the later :-)
See y'all in a few weeks...
Still, given the choice of checking these products out in detail or roaming around Italy, I think I'll stick with the later :-)
See y'all in a few weeks...
Sunday 18 May 2008
How a stateless ESXi infrastructure might work
Yep, it's Sunday afternoon, and thus time for another installment of Sunday Afternoon Architecture and Philosophy! Advance Warning: Get your reading specs, this post is a big 'un.
I've mused several times on the whole stateless thing, especially with regards to ESXi, today I'm going to take it a bit further in the hope that someone out there from VMware may actually be reading (besides JT from Communities :-).
Previously I've showed how you can PXE boot ESXi. While completely unsupported, it at least lends itself to some interesting possibilities, as with ESXi, VMware are uniquely positioned to offer such a capability. The Xen hypervisor may be 50,000 lines of code but it's useless without that bloated Dom0 sitting on top of it. Check out the video (if you can be bothered to register, are they so desparate for sales leads that you need to register to watch a video???) of the XenServer "embedded" product - it still requires going though what is essentially a full Linux install, except instead of reading from a CD and installing to a hard drive it's all on a flash device attached the mainboard. But i digress...
So lets start at the top, and take a stroll through how you might string this ESXi stateless infrastructure together in your everyday enterprise. And I'll say upfront, I'm a Microsoft guy so a lot of the options in here are Microsoft centric. In my defense however, every enterprise runs Active Directory and it's easy to leverage some peripheral Windows technologies for what we want to achieve.
First up, the TFTP server. RIS (or WDS) is not entirely necessary for what we want to do - a simple ol TFTP server will do, even the one you can freely install from a Windows CD. In this example we'll use good ol' pxelinux, so our bootfilename will be 'pxelinux.0' and that file will be in the root of the TFTP server. The directory structure TFTP root could be something as follows:
In the TFTP root pictured above I have 3 directories named after the ESXi build. The 'default' file in the pxelinx.cfg directory presents a menu so I can select which kernel to boot. I could also have a file in the pxelinux.cfg directory named after the GUID of the client, which would allow me to specify which kernel to boot for a particular client.
If you already have RIS / WDS in your environment, things are a little less clunky... can simply create a machine account in AD, enter the GUID of the box when prompted and then set the 'netbootMachineFilePath' attribute on computer object to the file on the RIS box that you want to boot.
Onto DHCP. Options 66 (TFTP server hostname) and 67 (bootfile name) need to be configured for the relevant scope. DHCP reservations for the ESXi boxen could also be considered a pre-requisite. The ESXi startup scripts do a nice job of picking that up and handling it accordingly.
So all this stuff is possible today (albeit unsupported). If ESXi doesn't have a filesystem for scratch space, it simply uses an additional 512MB of RAM for it's scratch - hardly a big overhead in comparison to the flexibility PXE gives you. Booting of an embedded USB device is cool, but having a single centralised image is way cooler. As you can see, there's nothing stopping you from keeping multiple build versions on the TFTP server, making rollbacks a snap. With this in place, you are halfway to a stateless infrastructure. New ESXi boxes can be provisioned almost as fast as they can be booted.
After booting, they need to be configured though... and that's where we move onto theory...
The biggest roadblock by far in making this truly stateless, is the lack of state management. There's no reason why VirtualCenter couldn't perform this function. But there's other stuff that would need to change too in order to support it. For example, something like the following might enable a fully functioning stateless infrastructure:
1) Move the VirtualCenter configuration store to Lightweight Directory Services (what used to be called ADAM), allowing VirtualCenter to become a federated, mutli-master application like Active Directory. The VMware Desktop Manager team are already aware that lightweght directory services make a _much_ better configuration store than SQL Server does. SQL Server would still be needed for performance data, but the recommendation for enterprises these days is to have SQL Server on a separate host anyway.
2) Enhance VirtualCenter so that you can define configurations on a cluster-wide basis. VirtualCenter would then just have to track which hosts belonged to what cluster. XenServer kind of works this way currently - as soon as you join a XenServer host to a cluster, the configurations from the other hosts are replicated to it so you don't have to do anything further on the host in order to start moving workloads onto it. This is probably the only thing XenServer does _way_ better than VI3 currently. Let's be honest - in the enterprise, the atomic unit of computing resource is the cluster these days, not the individual host. Additionally, configuration information could be further defined at a resource pool or vmfolder level.
3) Use SRV records to allow clients to locate VirtualCenter hosts (ie the Virtual Infrastructure Management service). Modify the startup process of ESXi so that it sends out a query for this SRV record everytime it boots.
4) Regardless of which VirtualCenter the ESXi box hit, since it would be federated it can tell the ESXi box which VirtualCenter host is closest to it. The ESXi box would then connect to this closest VC, and ask for configuration information.
By now all the Windows people reading this are thinking "Hmmm, something about that sounds all too familiar". And they'd be right - Windows domains work almost exactly in this way.
SRV records are used to allow clients to locate kerberos and LDAP services, ie Domain Controllers. The closest Domain Controller to the client is identified during the logon process (or from cache), and the client authenticates to this Domain Controller and pulls down configuration information (ie user profile and homedrive paths, group membership information for the user and machine accounts, Group Policy, logon scripts etc). This information is then applied during the logon process, resulting in the user receiving a fully configured environment by the time they logon.
I haven't had enough of a chance to run SCVMM 2008 and Hyper-V through their paces to see if they operate in this manner. If they don't, VMware can consider themselves lucky and would do well to get this functionality into the managment layer ASAP (even if it means releasing yet another product with "Manager" in the title :-).
If Microsoft have implmented this kind of functionality however, VMware needs to take notice and respond quickly. Given that the management layer will become more and more important as virtualisation moves into hardware, VMware can't afford to slip on this front.
Congratulations if you made it this far. Hopefully you've enjoyed reading and as always for this kind of post, comments are open!
I've mused several times on the whole stateless thing, especially with regards to ESXi, today I'm going to take it a bit further in the hope that someone out there from VMware may actually be reading (besides JT from Communities :-).
Previously I've showed how you can PXE boot ESXi. While completely unsupported, it at least lends itself to some interesting possibilities, as with ESXi, VMware are uniquely positioned to offer such a capability. The Xen hypervisor may be 50,000 lines of code but it's useless without that bloated Dom0 sitting on top of it. Check out the video (if you can be bothered to register, are they so desparate for sales leads that you need to register to watch a video???) of the XenServer "embedded" product - it still requires going though what is essentially a full Linux install, except instead of reading from a CD and installing to a hard drive it's all on a flash device attached the mainboard. But i digress...
So lets start at the top, and take a stroll through how you might string this ESXi stateless infrastructure together in your everyday enterprise. And I'll say upfront, I'm a Microsoft guy so a lot of the options in here are Microsoft centric. In my defense however, every enterprise runs Active Directory and it's easy to leverage some peripheral Windows technologies for what we want to achieve.
First up, the TFTP server. RIS (or WDS) is not entirely necessary for what we want to do - a simple ol TFTP server will do, even the one you can freely install from a Windows CD. In this example we'll use good ol' pxelinux, so our bootfilename will be 'pxelinux.0' and that file will be in the root of the TFTP server. The directory structure TFTP root could be something as follows:

In the TFTP root pictured above I have 3 directories named after the ESXi build. The 'default' file in the pxelinx.cfg directory presents a menu so I can select which kernel to boot. I could also have a file in the pxelinux.cfg directory named after the GUID of the client, which would allow me to specify which kernel to boot for a particular client.
If you already have RIS / WDS in your environment, things are a little less clunky... can simply create a machine account in AD, enter the GUID of the box when prompted and then set the 'netbootMachineFilePath' attribute on computer object to the file on the RIS box that you want to boot.
Onto DHCP. Options 66 (TFTP server hostname) and 67 (bootfile name) need to be configured for the relevant scope. DHCP reservations for the ESXi boxen could also be considered a pre-requisite. The ESXi startup scripts do a nice job of picking that up and handling it accordingly.
So all this stuff is possible today (albeit unsupported). If ESXi doesn't have a filesystem for scratch space, it simply uses an additional 512MB of RAM for it's scratch - hardly a big overhead in comparison to the flexibility PXE gives you. Booting of an embedded USB device is cool, but having a single centralised image is way cooler. As you can see, there's nothing stopping you from keeping multiple build versions on the TFTP server, making rollbacks a snap. With this in place, you are halfway to a stateless infrastructure. New ESXi boxes can be provisioned almost as fast as they can be booted.
After booting, they need to be configured though... and that's where we move onto theory...
The biggest roadblock by far in making this truly stateless, is the lack of state management. There's no reason why VirtualCenter couldn't perform this function. But there's other stuff that would need to change too in order to support it. For example, something like the following might enable a fully functioning stateless infrastructure:
1) Move the VirtualCenter configuration store to Lightweight Directory Services (what used to be called ADAM), allowing VirtualCenter to become a federated, mutli-master application like Active Directory. The VMware Desktop Manager team are already aware that lightweght directory services make a _much_ better configuration store than SQL Server does. SQL Server would still be needed for performance data, but the recommendation for enterprises these days is to have SQL Server on a separate host anyway.
2) Enhance VirtualCenter so that you can define configurations on a cluster-wide basis. VirtualCenter would then just have to track which hosts belonged to what cluster. XenServer kind of works this way currently - as soon as you join a XenServer host to a cluster, the configurations from the other hosts are replicated to it so you don't have to do anything further on the host in order to start moving workloads onto it. This is probably the only thing XenServer does _way_ better than VI3 currently. Let's be honest - in the enterprise, the atomic unit of computing resource is the cluster these days, not the individual host. Additionally, configuration information could be further defined at a resource pool or vmfolder level.
3) Use SRV records to allow clients to locate VirtualCenter hosts (ie the Virtual Infrastructure Management service). Modify the startup process of ESXi so that it sends out a query for this SRV record everytime it boots.
4) Regardless of which VirtualCenter the ESXi box hit, since it would be federated it can tell the ESXi box which VirtualCenter host is closest to it. The ESXi box would then connect to this closest VC, and ask for configuration information.
By now all the Windows people reading this are thinking "Hmmm, something about that sounds all too familiar". And they'd be right - Windows domains work almost exactly in this way.
SRV records are used to allow clients to locate kerberos and LDAP services, ie Domain Controllers. The closest Domain Controller to the client is identified during the logon process (or from cache), and the client authenticates to this Domain Controller and pulls down configuration information (ie user profile and homedrive paths, group membership information for the user and machine accounts, Group Policy, logon scripts etc). This information is then applied during the logon process, resulting in the user receiving a fully configured environment by the time they logon.
I haven't had enough of a chance to run SCVMM 2008 and Hyper-V through their paces to see if they operate in this manner. If they don't, VMware can consider themselves lucky and would do well to get this functionality into the managment layer ASAP (even if it means releasing yet another product with "Manager" in the title :-).
If Microsoft have implmented this kind of functionality however, VMware needs to take notice and respond quickly. Given that the management layer will become more and more important as virtualisation moves into hardware, VMware can't afford to slip on this front.
Congratulations if you made it this far. Hopefully you've enjoyed reading and as always for this kind of post, comments are open!
Wednesday 14 May 2008
Get rid of that pesky VMware Tools update notification...
I have enough issues with the "VMware Tools out of date" notification appearing in the VI client every time an ESX patch is applied... it's almost useless information, as generally there are no support issues with running the RTM version of Tools regardless of the patch level of the host.
But even more annoying is the default behaviour of the VI 3.5 version of Tools, which enables a visual notification in the systray (on Windows guests) if an update is available, which is controlled by the checkbox below:
Too bad if you happen to certify particular driver (ie Tools) versions with coporate SOE versions, like every large enterprise on this planet does. And say goodbye to your standards when a bleary eyed admin sees this little yellow exclamation in the systray at 2am and gets the idea that upgrading VMware Tools may solve whatever problem they got woken up for. Hopefully they'll remember to raise a retrospective change request after some sleep. I won't even begin to imagine what the curious VDI user might do.
Fire up your registry monitoring tool of choice and clear the checkbox, and you will invariably be directed towards a modification in HKCU, meaning if you want to effect a machine wide change you would need to load the default user hive and mod the value in there, as well as the all users hive.
Good news is that you can more easily control the display on a machine wide basis by modifying the (default) value of 'HKLM\SOFTWARE\VMware, Inc.\VMware Tools'. Setting it to a DWORD value of 0 is the equivalent of clearing the checkbox (yes i know by default it's a REG_SZ - just turn it into a DWORD).
For anyone out there even half as lazy as me, copy this into your install script after the tools installer has been run:
REG ADD "HKLM\SOFTWARE\VMware, Inc.\VMware Tools" /V "" /T REG_DWORD /D "0x0" /F
But even more annoying is the default behaviour of the VI 3.5 version of Tools, which enables a visual notification in the systray (on Windows guests) if an update is available, which is controlled by the checkbox below:

Too bad if you happen to certify particular driver (ie Tools) versions with coporate SOE versions, like every large enterprise on this planet does. And say goodbye to your standards when a bleary eyed admin sees this little yellow exclamation in the systray at 2am and gets the idea that upgrading VMware Tools may solve whatever problem they got woken up for. Hopefully they'll remember to raise a retrospective change request after some sleep. I won't even begin to imagine what the curious VDI user might do.
Fire up your registry monitoring tool of choice and clear the checkbox, and you will invariably be directed towards a modification in HKCU, meaning if you want to effect a machine wide change you would need to load the default user hive and mod the value in there, as well as the all users hive.
Good news is that you can more easily control the display on a machine wide basis by modifying the (default) value of 'HKLM\SOFTWARE\VMware, Inc.\VMware Tools'. Setting it to a DWORD value of 0 is the equivalent of clearing the checkbox (yes i know by default it's a REG_SZ - just turn it into a DWORD).
For anyone out there even half as lazy as me, copy this into your install script after the tools installer has been run:
REG ADD "HKLM\SOFTWARE\VMware, Inc.\VMware Tools" /V "" /T REG_DWORD /D "0x0" /F
Subscribe to:
Posts (Atom)